
Word Profile Tool
The creation of a citation file only begins to exploit the possibilities that electronic text corpora can contribute to the practice of lexicography and philology. Techniques from the field of computational linguistics can also be used to provide answers to questions that would be difficult or impossible to obtain without computational techniques. For example: What words commonly appear together? What words appear in similar contexts? What is the most common object of a given verb? How common or rare is a particular word? Is a word associated with a specific work, author, or genre? What grammatical or morphological features are commonly associated with different verbs?, etc.
At the same time, however, these automated knowledge discovery procedures are never perfect and can always be improved with user feedback. In the process of working with these tools, lexicographers and other expert users will have the opportunity to consider them in far greater detail than most users of a digital library system. In current systems, expert users execute searches and then annotate and refine their results without integrating the added knowledge back into the system. If this information can be integrated back into the digital system, we can develop a cycle where scholars can use tools from the digital library system, help refine them, and improve the overall system for other users.
These issues form the core of our investigations in Workpackage 2 and our work on the Word Profile Tool.
The primary source materials for any lexicon must be the 'citation file' or the database of words in the corpus covered by the dictionary. This database contains the passages where each word is used and other information that might illuminate its meaning. At its simplest level, the computer can automate the basic tasks of identifying the words in a corpus, constructing an index, and presenting passages where the words appear so that lexicographers can write the definitions. This description, of course, masks some of the complexities involved in this operation. Greek is a highly inflected language, and many inflected forms share few if any surface features with their dictionary form. In order to identify the words contained in a corpus, we must take advantage of the Perseus morphological analysis system that allows us to determine, for example, that moloumetha is a future form of the Greek verb blosko (to come or go) or that metri is a form of the noun meter (mother). Once these determinations have been made, it is then possible for us to create an index giving each dictionary form and the passages where that word appears.
With this index, we are able to present citation information so that it is most useful for the specific task oflexicography.
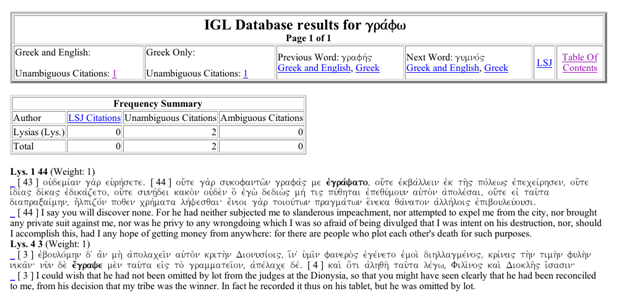
Figure 1: Sample Entry for Grapho from A Small Sample Database Based on Selected Texts of Lysias
We extract a key-word-in-context display for every occurrence of a word in the corpus along with English Translations from the Perseus Corpus where possible. These passages are presented in Chronological Order and accompanied by an author-by-author frequency summary. Links are also provided to the Online Edition of the Liddell, Scott, Jones Greek English Lexicon. As shown in the image below, the electronic lexicon shows both the lexicon entry and also statistical information about the word including comparative frequency data, word collocation information, and an automatically extracted list of words with similar definitions.
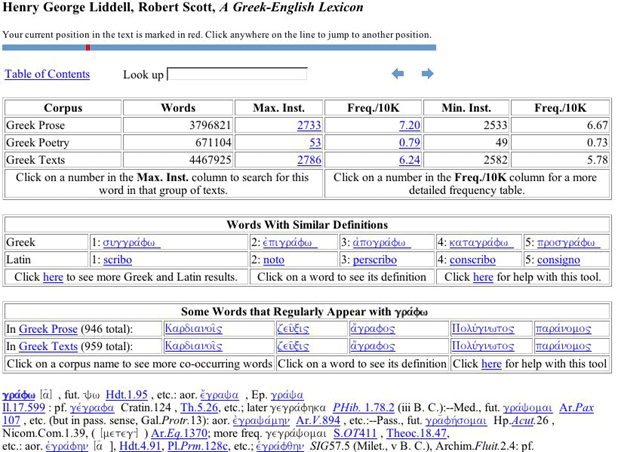
Figure 2: Sample Entry for Grapho from the Electronic LSJ
One of the primary problems faced by Lexicographers is scale. To offer only one example, there are more than 2,000 occurrences of this sample word grapho in the corpus for the new Intermediate Greek Lexicon and more than 53,000 occurrences of the very common word kai. In year three of the CHLT grant, we plan to explore methods for automatic categorization of some of these words based on their common subjects or objects, but in our first phase we have attempted to leverage the resources of existing reference works to help make this task more manageable. As illustrated in the figures below, our program mines citations from the existing LSJ, flags these passages, and presents them apart from the other citations in the order in which they appear in the Lexicon.

Figure 3: Sample KWIC entry for grapho Flagging First Three Citations from Dictionary Entry in Figure 2 Above
Our work had two primary areas of focus: 1. development of a DTD for the lexicon that will ultimately be written with the assistance of the word profile tool and 2. development of an infrastructure that will allow for the disambiguation of ambiguous Greek and Latin forms in a way that is useful to all the users of the digital library.
We initially believed that the lexicon that we would reintegrate into the digital library would be tagged according to the DTD defined by the Text Encoding Initiative. However, as we worked with this DTD we discovered that it was well suited for tagging existing lexica but not well suited for a resource that is 'born digital' and designed for reintegration into the digital library. From a lexicographic point of view, a DTD should provide a consistent structure so that XML validation can impose a consistency of style in addition to a consistency of coding.
For example, the TEI defines the following valid sub-tags for the <tr> or translation tag.
<!ELEMENT tr (#PCDATA | abbr | address | date | dateRange | expan | lang | measure | name | num | rs | time | timeRange | add | corr | del | orig | reg | sic | unclear | oRef | oVar | pRef | pVar | distinct | emph | foreign | gloss | hi | mentioned | soCalled | term | title | ptr | ref | xptr | xref | seg | bibl | biblFull | biblStruct | cit | q | quote | label | list | listBibl | note | stage | text | anchor | gap | alt | altGrp | index | join | joinGrp | link | linkGrp | timeline | cb | lb | milestone | pb)* >
This list means that the element <tr> may contain some text inside it [PCDATA] and also 63 other tagged elements, which may appear any number of times, in any order. The possible mathematical permutations are enormous. It gives the writer great freedom, but little guidance for composing an article.
Because this level of freedom does not suit our needs, in the past months we have carefully inventoried the elements that we want to include in each dictionary entry and developed a DTD that is better suited to the electronic creation of dictionary entries.
In our system, we have defined the <tr> element as follows:
<!ELEMENT tr (#PCDATA | or | expl)* >
This means that the translation may contain some text, the word 'or' (which we insert automatically in plain rather than bold text) and an explanation or comment which expands on the translation, and which is automatically bracketed.
This <tr> element has a simpler structure than the TEI one: and it also reflects our entry structure more accurately. We have written our system, or Document Type Definition (DTD), with this principle in mind. This enables us to have a very lean structure: we can model the lexicon with 90 of our elements rather than over 200 in the TEI, and, more importantly, each element has a simpler structure, containing less than 10 others within it, rather than 60.
This has two consequences:
We have taken the specific approach further, by defining each entry not by just one 'entry' element, but by six, chosen according to part of speech: describing nouns or adjectives, proper names, verbs, prepositions, sentence particles, and cross-references. This enables us to design each article according to the semantic requirements of each part of speech, again allowing a leaner structure. This is an innovation in dictionary tagging, and one that we hope may commend itself to other lexicographers.
Tagging will also make it easier for assistants to learn our methods of composition. If the lexicon manual is rewritten to cover the tagging, it will be easier for helpers to produce work in a consistent 'house style'.
After the lexicon has been written, we may find it advantageous to have a version of the lexicon that corresponds to the more flexible TEI DTD. Because our DTD is much simpler, this conversion will be easily accomplished with XSLT.
The second objective is to deliver a working system of expert knowledge integration. This will involve developing a user interface that allows our expert users to disambiguate morphological and lexically ambiguous word forms, and also to flag other interesting passages and integrate this knowledge back into the overall digital library system so that every user can take advantage of this improved knowledge. To accomplish this goal, we have developed a SQL database structure that is linked to the Perseus text display system. This system stores the following information:
System text identifier: Perseus:text:1999.01.0203 (happens to be the Cyropedia)
System text citation scheme: book=1:chapter=1:section=1 (where to look in the text)
Numbered Occurrence of the Form in the Section: 1 (in case the same word appears more than once in this
section)
Lexical Form: xrh=sqai (word that appears)
Lemma: xra/omai (headword it belongs to)
Correct Analysis: pres inf mp (in form output by Perseus morphological analyzer)
Of these, text identifier, citation, numbered occurrence, and lexical form point to the word while lemma and correct analysis point to the correct information.
As illustrated below, 'trusted users' can enter this information via an interface to the Perseus Digital Library. In this system, ambiguous forms are marked: unambiguous forms are green, morphologically ambiguous forms are red, and lexically ambiguous forms are blue.

Figure 4: Sample Text With Colored Links showing Types of Ambiguity
Clicking on an ambiguous link brings users to a form where they can see an interface with all of the possible parses and a simple web form where they can indicate the correct parse.

Figure 5: Disambiguation Interface
This information is then used in the indexing process so that any user who clicks on a word will see the correct form flagged rather than an unranked list of all possible forms. Likewise, when we build the Word Profile tool for this workpackage, forms that were previously marked as ambiguous now appear in the correct place as unambiguous forms.
Home | Partners | Collections | Documents | Workpackages