Cultural Heritage Language Technologies
Workpackage
2: Ancient Language Technologies
Year 3 Executive Summary
The final results of
Workpackage 2 can be divided into three groups: (i) multi-lingual retrieval
facilities for digital library systems, (ii) vocabulary profile tools for texts
and corpora, and (iii) a syntactic parsing tools for Greek texts. Our
first year was focused on the development of the vocabulary profile tools and
the integration of user feedback. The second year continued to focus on problems
of document architecture and establishment of unique identifiers for documents
in the system, as well as Multi-Lingual information retrieval facilities and
multi-lingual thesaurui automatically extracted from multi-lingual lexica.. We
also developed a search tool that used these thesaurui to generate Greek and
Latin search queries from queries that were initially entered in English. Our third year has focused the
development of a syntactic parsing toolbox that is designed to answer questions about the distribution
of grammatical features in texts, common subjects of verbs, and the
identification of modifiers in the free word order world of Ancient Greek and
Latin. We have completed the
syntactic parser on schedule and will give a demonstration at the final review.
Year 3 Results
In the past year, our work in WP 2 has focused on the continued creation of slips for the Greek Lexicon, the analysis of user feedback, the continuous refinement of the word profile tool in light of the feedback, and the creation of a syntactic parsing toolbox for Ancient Greek and Latin texts.
Continuing Development of the Word Profile Tool:
Our work on the word profile tool has focused in four primary areas:
1) improved identification of source passages cited in the Liddell-Scott-Jones Greek-English (LSJ) lexicon accomplished by both computational methods and extensive re-tagging of texts derived from the Thesaurus Linguae Gracae database;
2) transition from Beta Code and proprietary font encodings to Unicode;
3) improved integration of new material with the LSJ and the creation of an enfolded text that incorporates full texts and translation of the cited passages with the XML source of the lexicon;
4) continued writing of the lexicon with final publication scheduled for 2010 by Cambridge University Press and as an open access text as part of the Perseus Digital Library.
Syntactic Parsing Toolbox: (Deliverable 2.5)
We have developed a range of syntactic parsing tools in year 3. These tools have built on the data structure we built for the word profile tool. This data structure includes detailed grammatical information about every word in the corpus used by the lexicon such as part of speech, gender, number, case, tense, mood, voice, etc. We have completed experiments to discover grammatical relationships in sentences and to relate grammatical patterns to the contexts where they occur. Our most fruitful line of inquiry in this area has been a study of the use of the Greek participle in works by the orator Lysias to the narratives about violence in his judicial speeches.
The abstract for this work is as follows:
This paper explores the Greek participle and its use in the works of Lysias. I will argue that in Lysias’ works, narrative descriptions of violence are characterized by the unusually frequent use of the participle. I will further show that the association of high participle density and narratives about violence are a subset of a larger pattern relating to use of the participle in Lysias’ works. In this pattern, Lysias uses unusually large numbers of participles: (1) only within the narrative and argumentative sections of the speeches; (2) to structure the work and mark the conclusion of narrative arcs and lines of argument; (3) in their role as a structuring device, these passages also provide immediacy and momentum to the argument or narrative descriptions of events; and (4) to mark a return in subject matter to the case at hand and to focus the attention of the jury on the question that is before them.
This work was published in Literary and Linguistic
Computing 20.2 in 2005 (an offprint of this
article is included with this report.)
An account of the stages of development of the
parser in Year 3 is given in the following:
Our work on the syntactic parser was in three stages:
1) exploring state of the art, 2) parse tree building, 3) formation of data
structures, and (4) integration into the CHLT Digital Library System.
1) Establishing State of the Art
In the time that had passed since the initiation of
this project, much work was done by other scholars in syntactic parsing,
especially Steve Tinney’s group at the University of Pennsylvania who are
working on syntactic parsing for Sumerian yet still the following bibliography
was important for our work.
•
Chris Brew. "An Extensible Visualization Tool to Aid Treebank
Exploration." Linguistically Oriented Corpora workshop, Bergen,
1999, associated with EACL '99.
The tool is written in Lisp and runs
on a Macintosh.
•
Eric Brill, Mitch Marcus. "Tagging
an Unfamiliar Text with Minimal Human Supervision." In Proceedings
of the AAAI Symposium on Probabilistic Approaches to Natural Language, 1992, pages 10-16.
• * Michael A. Covington. "A Dependency Parser for Variable-Word-Order
Languages." Research Report AI-1990-01, University of Georgia. A
basic algorithm for handling languages for which phrase-structure trees are not
appropriate; examples in Russian and Latin.
•
Michael A. Covington. "Discontinuous Dependency Parsing of Free and Fixed
Word Order: Work in Progress." Research Report AI-1994-02,
University of Georgia. Shows how the techniques that work well for languages
with free word order can also work for languages like English.
•
Michael A. Covington. "A Fundamental Algorithm for Dependency Parsing."
Applies the algorithm from the earlier
paper to English, showing how to build projectivity back into the system.
•
Roberg Gaizauskas. "Investigations
into the Grammar Underlying the Penn Treebank II." Research
Memorandum CS-95-25, University of Sheffield.
• Nancy Ide, Patrice Bonhomme, Laurent Romary. "XCES:
An XML-based Encoding Standard for Linguistic Corpora." In Proceedings
of the Second International Language Resources and Evaluation Conference, 2000
• Robert T. Kasper, Mike Calcagno, Paul C. Davis. "Know When to Hold 'Em: Shuffling Deterministically in
a Parser for Nonconcatenative Grammars."
•
* Ulrich Koch. "The Enhancement of a Dependency Parser for
Latin." Research Report AI-1993-03, University of Georgia. Implementation
of Covington's algorithm, with some refinements; the article includes the code.
•
David M. Magerman and Mitchell P. Marcus. "Parsing
a Natural Language Using Mutual Information Statistics." In Proceedings
of the National Conference on Artificial Intelligence, 1990, 984-989. Uses mutual information to find
constituent boundaries; the assumption that constituents are contiguous is
essential. They claim their parser is "very good at parsing short
sentences of unrestricted texts without conjunctions" -- which means
"close to one error per sentence." Once there are conjunctions, the
error rate doubles; if the sentences get to be as long as 16-30 tokens, there
are 5 or 6 parsing errors per sentence.
•
Christopher Manning and Ivan Sag. "Dissociations
between Argument Structure and Grammatical Relations." In Lexical
And Constructional Aspects of Linguistic Explanation, ed. Gert Webelhuth, Jean-Pierre Koenig,
Andreas Kathol (Stanford: CSLI 1999), 63-78. See also the fuller version, from the 1995 conference at
which it was presented.
• Mitchell P. Marcus, Beatrice Santorini, Mary Ann
Marcinkiewicz. "Building a Large Annotated Corpus of English: The Penn
Treebank." Computational Linguistics 19(1994), 313-330.
•
Patrick Schone and Daniel Jurafsky. "Language-Independent
Induction of Part of Speech Class Labels Using Only Language Universals." This is a tease. Although they talk
about language-independence, they have only tested their algorithm with English
(using the Brown corpus). They are assuming that phrases are contiguous, and
they do not even acknowledge that this assumption is problematic. Their
decision tree is currently built only for SVO languages.
•
K. Sima'an, A. Itai, Y. Winter, A. Altman, N. Nativ. "Building
a Tree-Bank of Modern Hebrew Text."
•
Andrew Spencer and Louisa Sadler. "Syntax
as an Exponent of Morphological Features."
Discusses the analytic passives in
Latin.
•
Annie Zaenen and Hans Uszkoreit. "Language Analysis and Understanding." In Survey
of the State of the Art in Human Language Technology, ed. Joseph Cole et al. (Cambridge:
1996), 109-159.
2) Parse Tree Building
One of the key questions for our work package was
whether this sort of syntactic parsing can be undertaken using large, already
existing untagged corpora or if it is necessary to engage in the much more
labor intensive task of parse tree construction first. While the above research suggests that
automatic processes can provide a solid foundation, we constructed a more
rigorous evaluation of the question by creating a small number of hand
constructed parse trees and compared the results with those we obtained from
unparsed corpora. In year
three we created parse trees for four texts, Plato’s Apology, and three speeches by Lysias which can be used on
the CHLT-Perseus website. The by-hand parse trees provided better results.
3) Data Structures
We also
created data structures that
would allow for syntactic analysis and then developed a data structure for the
word profile tool that allowed us to flag citations in the Liddell Scott Jones
lexicon for the Cambridge lexicographers writing the dictionary. The database
was structured as follows:
+-----------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------+------+-----+---------+-------+
| lem | text | YES | MUL | NULL | |
| inflected | text | YES
| MUL | NULL
|
|
| weight | float | YES
| | NULL | |
| lang | text | YES
| |
NULL | |
| docid | text | YES
| MUL | NULL
|
|
| tail | text | YES
| MUL | NULL
|
|
| senid | text | YES
| MUL | NULL
|
|
| senlen | text | YES
| | NULL | |
| wpos | int(11) | YES | | NULL | |
| rcount | int(11) | YES |
| NULL | |
| type | text | YES
| |
NULL | |
| person | text | YES
| | NULL | |
| number | text | YES
| | NULL | |
| g_case | text | YES
| | NULL | |
| gender | text | YES
| | NULL | |
| voice | text | YES
| | NULL | |
| tense | text | YES
| | NULL | |
| mood | text | YES
| | NULL | |
| other | text | YES
| | NULL | |
+-----------+---------+------+-----+---------+-------+
We investigated this structure for use in syntactic
analysis. Initial results found
that it provided a strong foundation, but the granularity of the citation
detail was not fine enough for our needs.
The words were indexed by document id and byte offset of the first
character of the word in the document and this is a scheme that was initially
designed for information retrieval and it does not readily translate into the
human readable format that a philologist would expect when forming queries
about a text. Therefore, we also
developed a more human friendly layer for this data and conducted analyses so
that we could compare them to the analyses we obtained from parse trees.
4) Integration into the CHLT-Perseus Digital
Library System
We were able to link
syntactic parser tool the CHLT-Perseus system so that it would run in addition
to the Word Profile Tool and the Multilingual Information Retrieval Tool across
all CHLT texts. A demonstration of
the tools will be given at the review meeting. The best evidence the successful
use of these tools can be found in the following article:
Talking About Violence: Clustered Participles in the
Speeches of Lysias
Jeff Rydberg-Cox (Department of English, University of Missouri-Kansas City)
Literary and Linguistic Computing, May 2005
Abstract
This paper explores the Greek participle and its use in the works of Lysias. I will argue that in Lysias' works, narrative descriptions of violence are characterized by the unusually frequent use of the participle. I will further show that the association of high participle density and narratives about violence are a subset of a larger pattern relating to use of the participle in Lysias' works. In this pattern, Lysias uses unusually large numbers of participles: (1) only within the narrative and argumentative sections of the speeches; (2) to structure the work and mark the conclusion of narrative arcs and lines of argument; (3) in their role as a structuring device, these passages also provide immediacy and momentum to the argument or narrative descriptions of events; and (4) to mark a return in subject matter to the case at hand and to focus the attention of the jury on the question that is before them.
Other Publications in Year 3:
Humanities Computing, (book), Harcourt, 2005.
(forthcoming) (Table of Contents and first Chapter enclosed).
Approaching the Problem of Multi-Lingual
Information Retrieval and Visualization in Greek, Latin and Old Norse
Texts" (with Lara Vetter, Stefan Rüger, and Daniel Heesch). In Lecture
Notes in Computer Science from the European Conference on Digital Libraries 2004
"Cross-Lingual Searching and Visualization in
Greek, Latin and Old Norse Texts" (with Stefan Rüger, Lara Vetter, and
Daniel Heesch). Proceedings of
the 2004 Joint ACM/IEEE Conference on Digital Libraries. 383.
Plans for the Future:
The primary focus of our work-group for the future is, of course, the completion of the lexicon. We will continue to develop the Word Profile Tool to meet the needs of the lexicon group until it is ultimately completed. A second goal is determining how to provide public access to the tools we have created. The Word Profile Tool is a substantial philological research tool that would be of use to philologists working outside our research group. There are, however, rights issues with many of the texts derived from the TLG database. We have use rights for these texts, but not the rights to republish them on the web. We need to explore the extent to which we have created new texts that we can claim as our own and the extent to which we need to create a version of the database solely with Perseus tools. Finally, we need to develop a public use interface for the terms database that will allow access for a broader publc.
Reports on the Word Profile Tool
(D 2.1) and the Multilingual Information Retrieval Tool (D 2.4) are provided
here for reference, documentation on the Syntactic Parsing Tool (2.5) (provided
above) and demonstration given at Final Review Meeting, Text of 'Digital
Libraries' (sent as separate PDF files, marked JRC Digital Libraries).
_____________________________________________________
Word Profile Tool : D 2.1
Introduction
The field of classics has a long tradition of electronic editions of materials for the study of the ancient world. These electronic source materials have the potential to transform the way that humanists work with their sources. This is particularly true in the field of lexicography where computational techniques can substantially accelerate the task of gathering the source materials for dictionary entries. If we can automate the harmless drudgery of executing searches in an electronic corpus and compiling the results in a useful fashion, lexicographers can spend more of their time doing the intellectual work necessary to thoroughly consider words and their meanings.
The creation of a citation file only begins to exploit the possibilities that electronic text corpora can contribute to the practice of lexicography and philology. Techniques from the field of computational linguistics can also be used to provide answers to questions that would be difficult or impossible to obtain without computational techniques. For example: What words commonly appear together? What words appear in similar contexts? What is the most common object of a given verb? How common or rare is a particular word? Is a word associated with a specific work, author, or genre? What grammatical or morphological features are commonly associated with different verbs?, etc.
At the same time, however, these automated knowledge discovery procedures are never perfect and can always be improved with user feedback. In the process of working with these tools, lexicographers and other expert users will have the opportunity to consider them in far greater detail than most users of a digital library system. In current systems, expert users execute searches and then annotate and refine their results without integrating the added knowledge back into the system. If this information can be integrated back into the digital system, we can develop a cycle where scholars can use tools from the digital library system, help refine them, and improve the overall system for other users.
These issues form the core of our investigations in Workpackage 2 and our work on the Word Profile Tool.
Overview of the Word Profile Tool
The primary source materials for any lexicon must be the 'citation file' or the database of words in the corpus covered by the dictionary. This database contains the passages where each word is used and other information that might illuminate its meaning. At its simplest level, the computer can automate the basic tasks of identifying the words in a corpus, constructing an index, and presenting passages where the words appear so that lexicographers can write the definitions. This description, of course, masks some of the complexities involved in this operation. Greek is a highly inflected language, and many inflected forms share few if any surface features with their dictionary form. In order to identify the words contained in a corpus, we must take advantage of the Perseus morphological analysis system that allows us to determine, for example, that moloumetha is a future form of the Greek verb blosko (to come or go) or that metri is a form of the noun meter (mother). Once these determinations have been made, it is then possible for us to create an index giving each dictionary form and the passages where that word appears.
With this index, we are able to present citation information so that it is most useful for the specific task oflexicography. A sample of the slips is illustrated below and a sample based on a corpus of texts by Lysias is available at www.chlt.org/lysias

Figure 1: Sample Entry for Grapho from A Small Sample Database Based on Selected
Texts of Lysias
We extract a key-word-in-context display for every occurrence of a word in the corpus along with English Translations from the Perseus Corpus where possible. These passages are presented in Chronological Order and accompanied by an author-by-author frequency summary. Links are also provided to the Online Edition of the Liddell, Scott, Jones Greek English Lexicon. As shown in the image below, the electronic lexicon shows both the lexicon entry and also statistical information about the word including comparative frequency data, word collocation information, and an automatically extracted list of words with similar definitions.
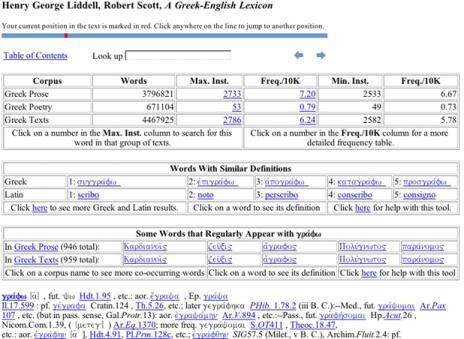
Figure 2: Sample Entry for Grapho from the Electronic LSJ
One of the primary problems faced by Lexicographers is scale. To offer only one example, there are more than 2,000 occurrences of this sample word grapho in the corpus for the new Intermediate Greek Lexicon and more than 53,000 occurrences of the very common word kai. In year three of the CHLT grant, we plan to explore methods for automatic categorization of some of these words based on their common subjects or objects, but in our first phase we have attempted to leverage the resources of existing reference works to help make this task more manageable. As illustrated in the figures below, our program mines citations from the existing LSJ, flags these passages, and presents them apart from the other citations in the order in which they appear in the Lexicon.

Figure 3: Sample KWIC entry for grapho Flagging First Three Citations from Dictionary Entry in Figure 2 Above
Reintegration of Expert Knowledge
Our work had two primary areas of focus: 1. development of a DTD for the lexicon that will ultimately be written with the assistance of the word profile tool and 2. development of an infrastructure that will allow for the disambiguation of ambiguous Greek and Latin forms in a way that is useful to all the users of the digital library.
Lexicon DTD
We initially believed that the lexicon that we would reintegrate into the digital library would be tagged according to the DTD defined by the Text Encoding Initiative. However, as we worked with this DTD we discovered that it was well suited for tagging existing lexica but not well suited for a resource that is 'born digital' and designed for reintegration into the digital library. From a lexicographic point of view, a DTD should provide a consistent structure so that XML validation can impose a consistency of style in addition to a consistency of coding.
For example, the TEI defines the following valid sub-tags
for the <tr>
or translation tag.
<!ELEMENT
tr (#PCDATA | abbr | address | date | dateRange | expan | lang | measure | name
| num | rs | time | timeRange | add | corr | del | orig | reg | sic | unclear |
oRef | oVar | pRef | pVar | distinct | emph | foreign | gloss | hi | mentioned
| soCalled | term | title | ptr | ref | xptr | xref | seg | bibl | biblFull |
biblStruct | cit | q | quote | label | list | listBibl | note | stage | text |
anchor | gap | alt | altGrp | index | join | joinGrp | link | linkGrp |
timeline | cb | lb | milestone | pb)* >
This list means that the element <tr> may contain some
text inside it [PCDATA]
and also 63 other tagged elements, which may appear any number of times, in any
order. The possible mathematical permutations are enormous. It gives the writer
great freedom, but little guidance for composing an article.
Because this level of freedom does not suit our needs, in the past months we have carefully inventoried the elements that we want to include in each dictionary entry and developed a DTD that is better suited to the electronic creation of dictionary entries.
In our system, we have defined the <tr> element as
follows:
<!ELEMENT
tr (#PCDATA | or | expl)* >
This means that the translation may contain some text, the word 'or' (which we insert automatically in plain rather than bold text) and an explanation or comment which expands on the translation, and which is automatically bracketed.
This <tr>
element has a simpler structure than the TEI one: and it also reflects our
entry structure more accurately. We have written our system, or Document Type
Definition (DTD), with this principle in mind. This enables us to have a very
lean structure: we can model the lexicon with 90 of our elements rather than
over 200 in the TEI, and, more importantly, each element has a simpler
structure, containing less than 10 others within it, rather than 60.
This has two consequences:
As it constrains the writer's options according to the structure and format of our entries, so it helps us to structure each article in a similar way, so creating a 'house style'.
Because, at every point in the article, the writer is presented with far fewer choices, the job of tagging is much easier and faster.
We have taken the specific approach further, by defining each entry not by just one 'entry' element, but by six, chosen according to part of speech: describing nouns or adjectives, proper names, verbs, prepositions, sentence particles, and cross-references. This enables us to design each article according to the semantic requirements of each part of speech, again allowing a leaner structure. This is an innovation in dictionary tagging, and one that we hope may commend itself to other lexicographers.
Tagging will also make it easier for assistants to learn our methods of composition. If the lexicon manual is rewritten to cover the tagging, it will be easier for helpers to produce work in a consistent 'house style'.
After the lexicon has been written, we may find it advantageous to have a version of the lexicon that corresponds to the more flexible TEI DTD. Because our DTD is much simpler, this conversion will be easily accomplished with XSLT.
Disambiguation
The second objective is to deliver a working system of expert knowledge integration. This will involve developing a user interface that allows our expert users to disambiguate morphological and lexically ambiguous word forms, and also to flag other interesting passages and integrate this knowledge back into the overall digital library system so that every user can take advantage of this improved knowledge. To accomplish this goal, we have developed a SQL database structure that is linked to the Perseus text display system. This system stores the following information:
System text
identifier:
Perseus:text:1999.01.0203
(happens to be the Cyropedia)
System text
citation scheme:
book=1:chapter=1:section=1
(where to look in the text)
Numbered
Occurrence of the Form in the Section:
1 (in
case the same word appears more than once in this
section)
Lexical
Form: xrh=sqai (word that appears)
Lemma: xra/omai (headword it belongs to)
Correct
Analysis: pres
inf mp (in form output by Perseus
morphological analyzer)
Of these, text identifier, citation, numbered occurrence, and lexical form point to the word while lemma and correct analysis point to the correct information.
As illustrated below, 'trusted users' can enter this information via an interface to the Perseus Digital Library. In this system, ambiguous forms are marked: unambiguous forms are green, morphologically ambiguous forms are red, and lexically ambiguous forms are blue.
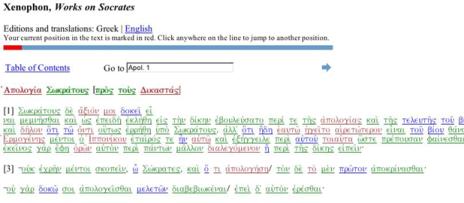
Figure 4: Sample Text With Colored Links showing Types of
Ambiguity
Clicking on an ambiguous link brings users to a form where they can see an interface with all of the possible parses and a simple web form where they can indicate the correct parse.

Figure 5: Disambiguation Interface
This information is then used in the indexing process so that any user who clicks on a word will see the correct form flagged rather than an unranked list of all possible forms. Likewise, when we built the Word Profile tool for this work-package, forms that were previously marked as ambiguous now appear in the correct place as unambiguous forms.
__________________________________________________________
D2.4: Multi-Lingual Information Retrieval Tool
Cross-lingual information retrieval is a particularly intriguing technology for students and scholars of Ancient and Early-Modern Greek and Latin or Old Norse. Works written in these languages are extremely important for understanding our literary, scientific, and intellectual heritage, but these languages are difficult and few people know them well. In particular, this technology can be extremely useful for non-specialist scholars and students who are somewhat familiar with these languages, but who do not know enough to form a mono-lingual query for a search engine. Students of Ancient Greek literature, for example, might want to know more about the quality of ‘cunning intelligence’ that is admired and exemplified in the character of Odysseus in Homer’s Odyssey. Because this quality is multifaceted, it would be very difficult for readers to formulate a query for this type of passage if they were working only with an English translation of the text; they must rely on the consistency of the translator. A cross-lingual information system, on the other hand, would help students identify key phrases —!such as the Greek word for cunning intelligence, ‘metis’ — and then study the passages where they appear. Such a system is, of course, only the beginning. At best, it can identify passages that need further study and translation since a user who cannot formulate a query probably cannot easily read the text in its original language either. While a great deal of work has been done on these sorts of systems in venues such as the Cross Lingual Evaluation Forum (CLEF) and the Translingual Information and Detection program (TIDES), their focus has largely been on business journals, newswires, and national security applications. Our work has focused on evaluating how the needs of students and scholars in the humanities differ from those in other domains and developing a system to meet these needs.
CONTEXT
AND TESTBEDS
The work described in this paper takes place in the context of the Cultural Heritage Language Technologies consortium (http://www.chlt.org), a jointly funded project of the National Science Foundation and European Commission Information Society echnologies Program. This project is a collaborative effort of eight partner institutions located in both the United States and Europe. Many of these partners have contributed corpora and core technologies that we have relied on in our work. Our testbeds for this project include the six million words of Greek and four million words of Latin with parallel translation from the Perseus Digital Library (http://www.perseus.tufts.edu); more than one million words of Latin drawn from early printed works in the history of science from Special Collections department at the Linda Hall Library in Kansas City (http://www.lindahall.org); a 750,000 word corpus of Early-Modern Latin from the Stoa
consortium at the University of Kentucky (http://www.stoa.org); a corpus of Isaac ewton’s alchemical, theological, and chemical papers from the Newton Project at Imperial College (http://www.newtonproject.ic.ac.uk/); and a corpus of Old Norse sagas from the University of California at Los Angeles. In addition to these textual test-beds, the Perseus Project has also provided its parsers and machine-readable dictionaries for Greek and Latin while the group at UCLA is creating comparable resources under the aegis of this project.
APPROACHES
TO THE PROBLEM
The problem of multi-lingual information retrieval is essentially one of machine translation on a very small scale. There have been two dominant approaches to this problem: 1) dictionary translation using machine-readable multi-lingual dictionaries and 2) automatic extraction of possible translation equivalents by statistical analysis of parallel or comparable corpora. There are, of course, other approaches. [1] points out that it is also theoretically possible to machine-translate target documents, but this technology is not yet feasible for most modern languages, let alone Greek, Latin, or Old Norse. See also [2] and [3] for an innovative approach based on topic modeling. Dictionary translation is a low-cost search technology that translates queries by substituting each word in a query with translations automatically derived from the machine-readable dictionary. This approach by itself is not very good, achieving results that are only 40-60% as effective as a mono-lingual search ([4-6]). The primary problems of this approach are related to the introduction of extraneous words and ambiguity into the query due to the multiple senses contained in most dictionary entries, the failure of most machine-readable dictionaries to account for technical terms in a consistent way, and the loss of important fixed phrases. Automatic extraction of translation equivalents from parallel or comparable corpora introduces similar sorts of ambiguity and carries two additional problems: 1) these corpora can be extremely expensive to produce, and 2) these automatically extracted translation equivalents are most effective in restricted omains ([7-9]). The needs and nature of our user community of students and scholars in a humanities digital library suggest that we can profitably adopt both of these approaches if we take appropriate steps to reduce query ambiguity. The nature of the corpus of Ancient Greek and Latin and Old Norse texts makes it ideal for this project, as it is highly domain specific within some broad parameters.2 Further, the corpus itself is very stable, so the cost of creating a parallel corpus is finite and the investment, once made, would have lasting value for students and scholars in its field. At the same time, these ancient languages have been highly studied and thus can benefit from the work of scholars who have developed comprehensive ‘unabridged’ lexica as well as domain specific dictionaries for both fields of discourse and specific authors. The information-seeking behaviors of the people who use digital resources in these languages also inform
our approach. Students and scholars of ancient languages are almost a ‘hyper-fit’ for the profile of a user of a multi-lingual information retrieval facility. Very few specialists are trained to write and speak Greek, Latin, or Old Norse; advanced training — for the most part — focuses on reading these languages. This focus on reading, however, means that the user community is trained in a philological approach that focuses on the use of small families of words and that is attuned to the shades of overlapping meanings of different words. The example in the introduction of a scholar studying ‘cunning intelligence’ is not random but drawn from a book-length study of the word metis ([11]). Further, even the most skilled readers of ancient languages are well versed in the use of reference works such as grammars and dictionaries and accustomed to using them regularly as they read. Classicist Martin Mueller describes the user community as follows: “Very few readers know ancient Greek well enough to read it without frequent recourse to a dictionary or grammar, and because of their highly specialized interests, the few readers who can do so are likely to be particularly intensive users of such reference works” ([12]).
The nature of our user community means that they are well equipped to help translate their query into the target language as long as they are provided with tools to help them in this process. In 1972, Salton query expansion thesauri, multi-lingual information retrieval tools could be as effective as mono-lingual tools ([13]). The information retrieval community has, however, eschewed Salton’s arguments for hand- constructed query expansion thesauri in favor of solutions that are more general and domain independent (i.e. [5], [8]). Salton’s carefully constructed thesauri are still expensive but this is an expense that can reasonably be shifted to each end user at query time for
humanities applications. A tool that helps them give feedback during the query translation process allows users to construct their own ad hoc query expansion thesauri, thus facilitating the construction of a query that is most useful for their needs. This approach does not preclude automatic disambiguation methods; as we will demonstrate below, we have developed a user feedback mechanism with tools to help end-users
translate queries including easy access to machine readable dictionaries and several query-specific statistical measures that assist users’ identification of relevant search terms.
2 In fact, the Thesaurus Linguae Gracae already defines 86 restricted domains for the surviving corpus of more than 71 million words written in Ancient Greek (see [10] and http://www.tlg.uci.edu)
QUERY
FORMATION
QUERY
TRANSLATION
The search facility begins with a simple interface that allows users to enter their search terms in English, to select the sources that will be used for query translation, and to restrict their results to words that appear in works written by a particular author.
Figure 1: Query Entry Screen Several of the options presented to the user in this phase are integrated with the larger digital library system and designed to scale up as new texts and reference works are added. The system for dictionary translation is based on a piece of middleware with a modular design that automatically extracts translation equivalents
from any SGML or XML dictionary tagged in accordance with the guidelines of the Text Encoding Initiative or any other user defined DTD. The author list restrictions are generated from the cataloging metadata from the digital library. After entering query terms, the user is presented with an interface with detailed information to allow them
to construct the best translation of the word for their needs. This process can range from the simple elimination of obvious ambiguities and mistakes to a careful consideration of every term. The interface provides a list of translation equivalents for the word or words that the user entered along with an automatically abridged English definition of the word, a link to the full definition for each word, a list of authors who use the words, and data about the frequency of each word in works by the selected authors.
Figure
2: Query Translation Screen
Query
Expansion
One of the challenges of this sort of multi-lingual information retrieval system is the dependence on a match between the concept that the user wants to study and the translation equivalents provided in the dictionary entry for the word. For example, a user interested in searching for Greek words that might mean ‘story’ will find several very good translation equivalents, including the Greek word muthos that means “speech, story or tale” and is cognate with the English word ‘myth,’ as well as other words such as ainos, meaning “tale or story,” and polumuthos, a compound word meaning “much talked of, famous in story.” The first phase will, however, miss other related words that do not happen to have the word ‘story’ as part of their definition, such as epos, defined as “that which is uttered in words, speech, tale.” To address this problem, we provide users with a query expansion option that suggests other words that are related to the exact matches returned by their initial query. These related terms are generated by an analysis of the definitions contained in the electronic machine-readable multi-lingual dictionaries. This
process involves extracting all of the translation equivalents from the dictionaries and stripping suffixes from the translation equivalents using Porter’s algorithm. We exclude translation equivalents where
!
df1
N
" .5
with N equal to the number of definitions in the dictionary. The terms themselves are assigned a binary weight rather than a weight such as tf x idf. Our experiments with various weighting schemes revealed that they had very little impact on the results because documents were very short (just over four words on average). Having developed this index, we determine the entries that are most similar to each other using a simple Dice similarity coefficient
(
!
sim(defi, def j ) = 2 defi "def j
defi + def j
).
The five words with the highest correlation coefficient are then included in the results for the query translation phase of the process. In many cases – as in the above example of a search for the word ‘story’ - this process enhances what are already very good search results. By its nature, this process expands recall at the expense of precision, thus running the risk of presenting the user with too much irrelevant information in the query translation phases. Therefore, a user seeking a more precise query can switch off the query expansion function.
Sources of Translation Equivalents
Our current research is focused on determining whether the work of Church and Gale for the Oxford English Dictionary [14] can be applied to our parallel corpora of Greek texts with English translations and Latin texts with English translations. Church and Gale argue that a ! 2 test can be used to determine translation equivalents in parallel corpora aligned at the sentence level. They posit a null hypothesis that words occur in parallel sentences independently or by chance. This null hypothesis is then compared with
the actual count of term co-occurrence across parallel corpora block using the following equation:
!
x
2 = (O" E)
2
E
with O equal to the number of times that a word pair appears together and E equal to
the average number of times that the terms would appear together if they were evenly distributed across the entire corpus. Our hope is that we will be able to generate a dynamic thesaurus of translation equivalents based on our corpora and offer this thesaurus to our users alongside the machine-readable dictionaries that we are currently using in this interface. Church and Gale’s results are intriguing, but we need to determine if they can be applied to texts written in Greek and Latin. We are focusing our investigations in three key areas. First, Church and Gale worked on business documents written in English and French drawn from the Union Bank of Switzerland corpus. Greek and Latin have much more complex morphological structures and very free word order, so it is necessary to study the impact of these linguistic differences when applying this algorithm. Second, our corpora are aligned with a much lower level of granularity than the corpus tested by Church and Hanks. Scholars traditionally refer to classical texts using a standard system, such as line number for poetry or page/paragraph numbers of an early printed edition for prose. For example, the works of Plato are referenced by a pagination system from a three-volume collection of Plato’s works published in 1578
by Henri Estienne. The three volumes were numbered consecutively and each page was divided into sections with the division marked by the letters a-e. Plato’s dialogues are cited using the name of the dialogue, the page number from this edition, and the letter from the section containing the beginning of the citation. Other prose works are divided in similar ways based on other early printed antecedents. Our parallel corpora of prose are aligned at this level and the resulting blocks can range from a few hundred words to almost one thousand words. Poetry is even more complicated because line numbers offer a false sense of precision. In actuality, the number of lines in a translation can vary widely between the original and the translation and — even when this is accounted for — word order conventions are so different that words could appear on widely different lines. We have obtained good preliminary results by working with aligned segments of ten lines, but we need to determine if this lower level of granularity will work generally across our corpora or – alternately - if we need to explore methods for working with comparable corpora rather than parallel corpora. Finally, this approach is similar to our query expansion routine in that it favors recall over precision. We will need a detailed study of our results to determine whether or not the information we are adding is useful
to users as they are translating their queries.