Workpackage 2: Computational Linguistics
Executive Summary
WP2: Second Year Accomplishments and Third
Year Goals
In the past year,
WP2 has focused its labor on the development of a multi-lingual information
retrieval tool. This tool has two
primary components:
1)
a facility to extract translation equivalents from our available digital
corpora
2) a user interface allowing users to
construct their queries for a traditional
mono-lingual
search engine.
We created the
core data for the query translation system using a program with a modular
design that automatically extracts translation equivalents from any SGML or XML
dictionary tagged in accordance with the guidelines of the Text Encoding
Initiative or any other user defined DTD. After entering query terms in
English, the user is presented with an interface with detailed information to
allow them to construct the best translation of the word for their needs. This process can range from the simple
elimination of obvious ambiguities and mistakes to a careful consideration of
every term. The interface provides
a list of translation equivalents for the word or words that the user entered
along with an automatically abridged English definition of the word, a link to
the full definition for each word, a list of authors who use the words, and
data about the frequency of each word in works by the selected authors. We also
experimented with automatic extraction of translation equivalents from the
parallel Greek and Latin corpora of the Perseus Digital Library and met with
only limited success. The
methodologies we used were based on work done with parallel corpora where all
documents were of comparable size.
Because of the heterogenous nature of our corpora and the varying sizes
of our available text chunks, we achieved far too many ‘false positives’ in our
results to be of any use to the average user. We were more successful in implementing a ‘query expansion’
routine that provides the user with possible suggestions of words that were not
in their original query by automatically extracting related definitions from
the TEI-conformant lexica. This
work was integrated with the results of WP1. After a user uses the WP2 multi-lingual search tool to
construct his or her query, it can be passed off to the mono-lingual
visualization tool of WP1 for further study and refinement.
Our second year also saw the continuation of our efforts to capture
feedback about the word study tool and re-integrate it into the database. This took several forms including
further editing of texts to achieve better extraction of parallel Greek and
English text segments. Our work
here had overlap with the alignment work we attempted for the multi-lingual
search tool. Because we did not
need to subject these texts segments to further statistical processing, our
insertion of milestones was more successful for this purpose. We also worked to reintegrate
other forms of existing knowledge into our database by mapping the citation
scheme of poetic works in older reference works such as the Liddell, Scott,
Jones Greek English Lexicon to the more
current and widely used standards established by the Thesaurus
Linguae Graecae. Finally, we continued work on the document
architecture for the lexicon with a particular focus on transformations that
will be appropriate for both the print edition and integration into the digital
library system.
In our third year,
we will turn our attention to our syntactic parsing toolbox. In this phase, we will try to develop
programs to discover selectional preferences and subcategorization frames for
Greek verbs. Our first step will
be to develop an architecture that allows for detailed statistical analysis of
sentences in Greek. Our initial
hypothesis is that we will be able to refine the interface that we developed
for the vocabulary profile tools and then turn to the statistical
analysis.
Quarterly
Progress Reports for Year 2
À
Cultural
Heritage Language Technologies
IST –2001-32745
June 1 – August 31, 2003
Workpackage
2:Word Profile Tools
University of Missouri, Kansas City
Faculty of Classics, Cambridge University
Bruce Fraser
Jeffrey A. Rydberg-Cox
A.A. Thompson
1.
Summary of key indicators of project progress
1.1 Overview
of objectives
The practical tools under development in Workpackage
2 can be divided into three groups:
1) Multi-lingual retrieval facilities for digital
library systems (DLSs).
2) Vocabulary profile tools for texts and corpora (in
DLSs).
3) Syntactic parsing tools for Greek texts.
1.2 Overall
assessment of main milestones, results, or deliverables
Our
first year was focused on the development of the vocabulary profile tools and
the integration of user feedback.
Work in this area has continued in this period with a continued focus on
problems of document architecture and establishing unique identifiers for
documents in the system. At the
same time, we began work on the
Multi-Lingual information retrieval facilities. Our next deliverable in this area is a multi-lingual
thesaurus that has been automatically extracted from our parallel corpora. Our initial focus has been on
data structures for aligning our parallel corpora and the most appropriate
algorithms for our use.
2. Work Progress Overview
2.1
Specific objectives for the reporting period
We have had three specific objectives for this
reporting period.
1. To
continue working on the document architecture for the lexicon with a particular
focus on transformations that will be appropriate for both the print edition
and integration into the digital library system.
2. To
continue developing a mechanism that will allow for better integration of
pre-existing expert knowledge into the word profile tool, with a particular
emphasis on mapping the citation scheme of poetic works in older reference
works such as the Liddell, Scott, Jones Greek English Lexicon to the more current and widely used standards
established by the Thesaurus Linguae Graecae.
3.
Preliminary work for D2.3: “Tool to Extract Corpus Based Thesauri from
Corpora”.
2.2 Achievements
Document Architecture:
The architecture of the Greek
lexicon needed to have a design which is
suitable for both the print edition and the digitized version. The development of a dedicated document
structure or Document Type Definition (DTD) was described in the Progress
Report for February-March 2003. However, the individual documents also need to
be linked into a unified system which allows for a wide variety of textual
interrogation, and they also require suitable XSL transformations for display
in the print and digital versions. Document linking is described briefly first.
Linking documents:
We initially
contemplated the 'XLink' system, which uses a single file which contains all
the links for the entire lexicon, in the form:
<interlink>
<fromPoint
href="Filename.xml#ID_OfSomeElementOrAnchor" />
<toPoint
href="OtherFilename.xml#ID_OfThingToLinkTo" />
<go
/>
</interlink>
However, we decided that it was
possible to link documents in a more straightforward structure, through direct
HREF linking between the documents, with all external linking achieved with the
'headword' of an entry as the target. This created a much simpler architecture.
Each document may also contain a
number of document-internal links, using attributes to the elements
<RefFm>, <RefVL>, and <Form>. Of these, <Form> points
to the HL within a single entry. <RefVL> and <RefFm> occur only
within cross-reference entries, and refer to a variant or other form of the
headword, within whichever entry is the target of the <Ref> element.
The <Ref> element always
refers to a headword, and its attribute carries the only HREF link which can
point to a target headword external to the document. Every document in the lexicon carries a unique
identifier, and the headwords that appear in it carry a 'name' attribute
(applied during production). We anticipate that this structure, in conjunction
with the finely-structured DTD, will support a wide variety of textual
interrogation.
XSL transformations
It is desirable to have a
high-quality display, both for feedback during the authoring process, and also
for reader use, since the lexicon is so densely formatted, using Greek, italic,
bold and bracketted text. We especially wish to avoid the almost unreadable
texts of some earlier classical-language dictionaries. We are therefore using
XSL-FO transformations, which are capable of generating print-quality output,
with precise determination of text detail, as well as whitespace, indents, and
other aspects of the overall appearance of the document. The transformations are still in the
process of development. The output so far achieved is exemplified by the PDF
file included here as an appendix (see Annex 2). An extract from the coding is given here:
<!-- *****
fo:page-sequence mode ***** -->
<!-- Creates
fo:page-sequence elements -->
<xsl:template
match="lex:lexicon" mode="fo:page-sequence">
<fo:page-sequence
master-reference="lexicon-page-sequence">
<xsl:apply-templates select="."
mode="fo:title" />
<xsl:apply-templates select="."
mode="fo:static-content" />
<xsl:apply-templates select="."
mode="fo:flow" />
</fo:page-sequence>
</xsl:template>
<!-- ***** fo:title mode
***** -->
<!-- Creates a fo:title
element -->
<xsl:template
match="lex:lexicon" mode="fo:title">
<fo:title>
<xsl:value-of select="lex:header/lex:file/lex:title"
/>
</fo:title>
</xsl:template>
<!-- *****
fo:static-content mode ***** -->
<!-- Creates
fo:static-content elements -->
<xsl:template
match="lex:lexicon" mode="fo:static-content">
<fo:static-content flow-name="running-head-recto">
<xsl:apply-templates
select="lex:header" mode="fo:static-content" />
</fo:static-content>
<fo:static-content
flow-name="running-head-verso">
<xsl:apply-templates
select="lex:header" mode="fo:static-content">
<xsl:with-param name="side"
select="'left'" />
</xsl:apply-templates>
</fo:static-content>
<!--
<fo:static-content flow-name="footer">
<fo:block>Footer</fo:block>
</fo:static-content>
-->
</xsl:template>
<xsl:template
match="lex:header" mode="fo:static-content">
<xsl:param name="side"
select="'right'" />
<fo:block xsl:use-attribute-sets="lex:normal-font
lex:italic-font"
font-size="9pt" text-align="{$side}"
space-before="{$fo:region-before-extent} - 11pt"
border-bottom="0.5pt solid black">
<xsl:value-of
select="lex:file/lex:title" />
<xsl:text> </xsl:text>
<xsl:value-of
select="lex:file/lex:date" />
</fo:block>
</xsl:template>
<!-- ***** fo:flow mode
***** -->
<!-- Creates a fo:flow
element -->
<xsl:template
match="lex:lexicon" mode="fo:flow">
<fo:flow flow-name="xsl-region-body"
font-size="8.5pt" line-height="10pt"
text-align="start">
<xsl:apply-templates
select="lex:text" mode="fo:block" />
</fo:flow>
</xsl:template>
<!--
<xsl:template
match="lex:AdvUsg | lex:Alt | lex:Ann | lex:Au |
lex:Case | lex:Cllc | lex:Cmpl | lex:Ctxt |
lex:Def | lex:Deg | lex:DInfl | lex:DL |
lex:Ed | lex:Encyc | lex:Envr | lex:Ety | lex:Extra |
lex:Form | lex:Func |
lex:GLbl | lex:Gntv | lex:Gr |
lex:HL |
lex:Indic | lex:Infl | lex:ital |
lex:Lbl | lex:LblR |
lex:Md |
lex:Obj |
lex:Prnth | lex:PrPhr | lex:PrpUsg | lex:Prsd | lex:PS |
lex:QualN |
lex:RefFm |
lex:Spec | lex:Subj | lex:Summ |
lex:title | lex:Tns |
lex:Tr | lex:TrPhr |
lex:Usg |
lex:Vc | lex:VInfl | lex:VL |
lex:Wk |
lex:XR" mode="fo:inline">
<xsl:text> </xsl:text>
<xsl:apply-imports />
</xsl:template>
<xsl:template
match="lex:Lbl" mode="fo:inline">
<xsl:text> </xsl:text>
<xsl:apply-imports />
<xsl:text> </xsl:text>
</xsl:template>
-->
<!--
<xsl:template
match="*[not(preceding-sibling::node())] |
lex:hyph | lex:Hm" mode="fo:inline">
<xsl:apply-imports />
</xsl:template>
<xsl:template
match="*" mode="fo:inline">
<xsl:text> </xsl:text>
<xsl:apply-imports />
</xsl:template> -->
(See also Annex 2.)
Integration of Expert Knowledge:
The development of the word profile
tool has faced two major interrelated problems in the integration of primary
textual data. The first is that the corpus is not static: new textual
information is continually being discovered, especially in the Oxyrhynchus
papyri, which have been published regularly since 1898, with approximately
another 40 volumes due to appear. The second is that Ancient Greek poetic texts
have been edited using multiple citation systems, many of which were devised in
the nineteenth century.
A binary search procedure was
designed to overcome both problems. The Perseus morphological analyzer can
search throughout all relevant textual databases in the DLS, including
newly-digitized texts as they become available. This will be particularly
useful for Hellenistic (post-classical) Greek texts, where many important new
discoveries are being made.
The second problem, of multiple
citation systems, is especially severe for early lyric poets such as Sappho,
whose works are preserved mostly in fragmentary state. Therefore, as well as
the equivalence tables described in the Progress Report for June-November 2002,
we have also built tables for the poets, which will be integrated in the search
software. The morphological analyzer can then conduct separate searches which
are restricted to passages cited in reference works such as the Liddell and
Scott Greek Lexicon (LSJ), and match the old citations to the digitized texts.
Outputs from the two types of searches can then be used for scholarly research,
in tandem or separately.
The equivalence tables will also
have a more general reference use for classical literary and linguistic
studies, as they will enable readers of LSJ and other reference works to
identify passages in the modern editions. They will therefore also be published
in print form.
An extract from the introduction
to the human-readable version follows. See also a sample from the table,
included as Annex 1.
[Extract from Introduction
begins]
When using the Greek-English
Lexicon of Liddell-Scott-Jones (LSJ), readers face the problem that many
citations of the early Greek poets are to editions which are out of print and
have been superseded by more recent works which give different numbers to the
fragments. Although their comparationes numerorum provide helpful 'back bearings' to the earlier editions, they do not
constitute a fast method of linking from citations in LSJ to the texts. In
addition, users of the Thesaurus linguae Graecae (TLG) CD-ROM may
have no access to them, and citations in Montanari and the DGE cannot always
be matched to LSJ. The authors and works covered are summarized below, grouped
approximately by genre.
Lyric and iambic poets
Mappings are given for Alcaeus,
Alcman, Anacreon, Archilochus, Bacchylides, Callimachus (Aet., Epigr., Hec.,
Iambi, fragments), Carmina
popularia, Corinna, Hipponax, Ibycus, Ion, Lyrica
adespota (in Page PMG listed as Fragmenta
adespota), Philoxenus, Pindar (Paeanes, Parthenia, Dithyrambi), Praxilla, Sappho, Scolia (Carmina convivalia in PMG), Simonides, Stesichorus, Timocreon,
and Timotheus.
Epigrams
Epigrams by lyric and iambic
poets are included in their listings. Citations from the Anthology (AP, APl.,
and App.Anth.) retain the same
numbering in most modern editions, apart from the collections of Gow &
Page, whose indexes are cited.
Bucolic and elegiac poets
Poets are not included if their
early numbering is retained in modern editions. These authors include:
Callinus, Demodocus, Mimnermus, Moschus, Pratinas, Semonides, Solon,
Theocritus, and Tyrtaeus. However, the fragments
of Bion are mapped, and the division of Theognis into Books 1 and 2 is
given.
Epic fragments:
Citations of epic fragments in
old editions are mostly from Allen, and sometimes from Kinkel. Mappings from
both are given for Cypria, Epigoni, Il.Parv.,
Il.Pers., Nosti, and Titanomachia. For Hesiodic fragments, readers are directed to the
concordance in Merkelbach-West.
Comic fragments
While most fragments of
Aristophanes and Menander have the same numbering in old and new editions, much
new material has been discovered, and fragments have been extensively
renumbered. References are given to Kassel-Austin's PCG III.2 (for
Aristophanes) and VI.2 (Menander). For Menander, mappings are given for line
numbers of named plays, and for fragments which appear in Sandbach.
Philosophical fragments
Old editions cite from Diels Vorsokr.
or PPF. As the same numbering is retained in Diels & Kranz and KRS,
it is not given here. The editions are cited in the bibliography.
Tragic fragments
Citations of Aeschylus and
Sophocles have the same numbering in most editions, so these are cited, and
mappings are given to Diggle TGFS. Mappings are also given for citations
of Aeschylus from Weir Smyth AJP, and, for Euripides, from Arnim to Page
Select Papyri, Bond, and Diggle Phaeth.
[Extract from Introduction
ends. See also Annex 1].
Preliminary Work for D2.3: “Tool to Extract Corpus
Based Thesauri from Corpora”
Work
on Deliverable 2.3, a tool to extract a corpus based thesaurus from our
parallel corpus of Greek and Latin texts focused in two areas. First, we looked at document
architecture to allow for more precise alignment of texts. The Perseus Text Display system can
display parallel segments of Greek and Latin texts but the level of granularity
is very high. The only map points
available are the ones defined by the <div> or <milestone> tags and
declared in the <refsdecl> tag of the TEI header. While this mechanism is appropriate for
works such as Greek Rhetoric where the standard citation system is usually no
more than a paragraph or two, it is less appropriate for poetry and drama where
milestones might be 200 or more lines apart and the div structure might present
entire scenes from a play.
Therefore, we have developed a system for automatic text alignment that
takes advantage of a facility in the Perseus text display system that allows us
to get a precise citation that includes a line number for the beginning of any
particular sentence. For example,
a display chunk of book 1 of Homer’s Iliad in our system will offer parallel translations of lines 33 to 65 but it
is possible to use the byte-offset in the XML file to discover that the
sentence “ennêmar men ana straton ôicheto kêla theoio…” begins at line 53. Our approach, therefore, for texts structured with line
numbers like this one is to get the citation information for every sentence in
both the Greek and English version of the texts, round the line number down to
the nearest 10 and then use that citation as an alignment point for chunks of
text. This data is
stored in a SQL database with the following structure:
Attribute | Type | Modifier
-----------+---------+----------
sennum
| integer |
docid
| text |
tail | text |
lang | text |
senid
| text |
senlen
| text |
toplevel |
text |
cit | text |
dcit | text |
Where
dcit is the rounded citation for each sentence. We then select all of the sentences from the Greek and
English versions of the text with the same dcit value and use the resulting
sentences as the basis to calculate possible translation equivalents.
The second portion of this work has focused on
evaluating approaches that will be successful for texts written in Greek,
Latin, and Old Norse. We have
focused our investigations on three different equations, a Chi-squared test, a
t-score and a mutual information score.
In our initial investigations, the chi-squared test appears the most
promising since mutual information scores are highly sensitive to variation in
words that occur with relatively low frequencies. Similarly and t-scores assume the normal distribution of
probabilities of words occurring together and Zipf’s law shows that this
assumption is not true. At this
point, work is proceeding with the chi-squared test as we develop the
multi-lingual thesaurus tool.
2.2.2
Progress of Workpackage/Tasks
We are on track to deliver D2.3 on
time.
2.3.2
Work planned for next reporting period
Continued work on multi-lingual
information retrieval tool and document architecture issues. Completion of the citation scheme map
and its integration into the word study tool.
3.1
Co-operation within the consortium, including project meetings
Project meeting in Cambridge between the three
project members JRC, BLF and AAT, 9-10 June, 2003.
Consortium liaison meeting in London, with
representatives of all participating institutions, 12 June, 2003.
3.2
Participation in workshops, conferences, publications
PUBLICATIONS:
"Automatic
Disambiguation of Latin Abbreviations in Early Modern Texts for Humanities
Digital Libraries" in Proceedings
of the 2003 Joint Conference on Digital Libraries"
"Towards a Cultural Heritage Digital
Library" (with members of the Perseus Project) in Proceedings of the 2003 Joint Conference on
Digital Libraries
CONFERENCES:
Joint Conference on Digital Libraries, Houston Texas, May 28 – June 2, 2003.
Annex 1: Equivalence Table for poetic texts (extract):
Carm.Pop. =
CARMINA POPULARIA TLG
0295, 001
(Bergk III pp.654-88 to PMG pp.449-470; GL V
pp.232-269.)
LSJ PMG
1 3 849
2 34 880
3 PMG,
Fr.adesp. 37 = 955
4 26 872
5 33 879
6 25 871
7-8 5 851
9 31 877
10 16 862
11 33 879
12 14 860
13 1 847
14 17 863
15 20 866
16 19 865
17 18 864
18 24 870
19 6 852
20 30 876
21 30 876
22A 30 876
22B 15 861
23 22 868
24 4 850
25 35 881
26 13 859
27 7 853
28 IEG
II p.11, Adesp.eleg. 17
(TLG
0234, 001 Elegiaca adespota)
29 Ath.
10.455D (83, 2-3)
30 Tryphon
p.193, 18
31 Ath.
10.453B (78, 22)
32 Ath.
10.453B (78, 23)
33 Ath.
10.455D (83, 8)
34 IEG
II p.93, Panarces (a)
35 Plu.
Quom.adul. 54 B 6
36-38 Ath.
14.648F (60, 10-20)
LSJ PMG
39 28 874
40 IEG
II p.8, Adesp.eleg. 7
(TLG 0234, 001 Elegiaca adespota)
41 2 848
42 36 882
43 23 869
44 27 873
45 21 867
46-47 Coll.Alex.
pp.173, 138
Corinn. = CORINNA
Lyr.
TLG 0294, 001
(Bergk III pp.543-53 to PMG pp.325-45; GL IV
pp.18-69.)
LSJ citations marked "Corinn.Supp." are given separately.
LSJ PMG
1 5 658
2 9 662
3 20 673
4 10 663
5 8 661
6 6 659
7 3 656
8 16 669
9 4 657
10 11 664
11 13 666
12 31 684
13 2 655
14 22 675
15 22 675
16 22 675
17 22 675
18 22 675
19 7 660
20 2 655
21 11 664
22 25 678
23 21 674
24 24 677
25 26 679
26 23 676
27 33 686
28 1 654
29 15 668
30 17 670
31 18 671
32 12 665
33 19 672
34 35 688
35 27 680
36 28 681
37 29 682
38 30 683
40 32 685
41 34 687
42 36 689
Corinn.Supp.
LSJ PMG
1 1
(a) col. 1 654
(a), col. 1
2 1
(a) col. 3 654
(a) col. 3
Cypr. = CYPRIA
TLG 1296, 001 (Bernabé)
Allen 118-125, Kinkel 15-32, Davies, Bernabé, West.
Allen K. Davies
Bernabé West
1 1 1 1 1
2 2 2 2
3 2 3 3 4
4 3 4 4 5
5 4 5 5 6
6 5 6 8 9
7 6 7 9 10
8 7 9 11 15
10 12 13 12
11 9 13 15 16
12 8 11 14 14
13 10 15 17 18
14 11 p.75,
4 21 19
15 12 17 24 20
16 13 p.160,
4 25 21
17 14 18 26 22
18 15 21 27 23
19 16 22 28 24
20 17 19 29 26
21 18 20 30 27
22 19 23 31 28
23 20 24 18 29
24 21 26 32 30
25 22 25 33 31
26 p.52.n. 34
Epigoni
TLG 1351, 001 (Bernabé)
Allen 115, Kinkel 13-14, Davies, Bernabé, West.
Allen K. Davies
Bernabé West
1 1 1 1 1
2 2 p.74,
1 5 3
3 3 2 2 5
4 4 3 3 4
E. = EURIPIDES Trag.
TLG 0006
Most frr. in LSJ are from Nauck, and retain the same numbers
in TLG (as work 020). They include most of the passages in Diggle Phaeth.
(many of which also appear as TLG work 023).
Frr. collected in CCL have Nauck numbers in the text and
apparatus, and follow Diggle for Phaeth.
Recent frr. appear in Austin, and in the collections of
Jouan-Looy (who cite the numbering of Kannicht and Mette 'E.'), and Kannicht.
Frr. are organised in four groups: from Nauck to Diggle, Hyps., other named plays, and plays cited only in the LSJ
Authors and Works listing.
1) Frr. from Nauck
to page numbers in Diggle TGFS:
Nauck Diggle
TGFS
187; 206 pp.85-6
228
94
282 96
285; 286; 292 98-100
360 101
362 104
453 114
472; 997
115-6
484; 494; 495; 499 122-4
506 127
670 131
752 135
771; 772 151
777-9; 781 156-7
821 162
819 165
839 166
898; 910; 912 167-9
2) E.Hyps. is mapped from Hunt to Bond (TLG
work 026). LSJ cites variably by fr., sometimes column, and line. See also CCL
II, Jouan-Looy 3 pp.176-223.
LSJ Bond
1 I
i
1 ii I
ii
I iii I
iii
I iv I
iv
3 (1) or 3 (1) i I
i
3 ii or 3 (1) ii I
ii
iii or 3 iii I
iii
3 (1) iv or
5 or 5 (3) I
iv
7 or 9 7
16 (18) 18
32 or 32 (58) 58
34 or 34 (60)
or 34 (60) i 60
41 or 41 (64) 64
44 70
57 57
60 or 60 i 60
64 64
3) Other named plays
(marked with an asterisk in the LSJ Authors and Works listing)
are cited from Arnim. The letter 'A' is sometimes appended (details below).
Most appear in Page Select Papyri (TLG work 029).
E.Antiop.
is usually cited by papyrus column A or B (mostly preceded by ii or iv
respectively) and line number, with 'A', 'Arn.', or 'Arnim' following.
Occasionally, Arnim page numbers are given. See also CCL II, Jouan-Looy 1
pp.240-274.
Arnim Page
ii A 7 A (Nauck
fr.185, 3)
iv B (line) A
(or Arn. or Arnim) fr.10
B 58 p.21 A fr.10, 58
p.21 A fr.10, 66
(Other fragments from column A are collected in Nauck as
frr.179, 181,
183-221, and also appear in Arnim).
E.Cret.
(Also see CCL I,
Jouan-Looy 2 pp.322-32.)
(line) fr.11
E.Melanipp.Capt.
(CCL I, Jouan-Looy 2 pp.384-96.)
Fr.6.11 fr.13, 7
E.Melanipp.Sap.
(CCL I, Jouan-Looy 2 pp.376-384.)
Prol.15 fr.14, 15
E.Oen.
(Jouan-Looy 2 pp.468-75.)
p.39 A or fr.4 A fr.28
(Other frr. from Arnim - p.39 fr.6, p.39 fr.5 and p.40 fr.6
- are collected in TLG as work 030.)
E.Pirith.Oxy.2078
Fr.1.14 fr.15a, 8
E.Sthen.
(CCL I, Jouan-Looy 3 pp.22-7.)
Prol.25 fr.16, 18
Prol.35 fr.16, 28
p.44A fr.16, 18
4) Despite the Authors
and works listing, E.Archel. is not cited by LSJ. The passage in Arnim is
published by Austin as fr.19 (TLG work 021). See also CCL II, Jouan-Looy
1 pp.292-307.
Frr. from E.Phaëth. are collected in Diggle Phaeth. (TLG
work 023). They are cited in LSJ only by Nauck fragment numbers, which are
given here, with the other passages in Arnim, matched to Diggle. (See also CCL
I, Jouan-Looy 3 pp.248-67.)
Nauck Arnim Diggle
fr.771 p.67, 1-5 1-5
fr.772 p.68, 6-7 6-7
pp.68-9,
1-37 8-43
fr.773 pp.69-72, 1-77 44-120
fr.774 p.72, 86-8 124-6
pp.72-3,
89-118 127-57
fr.775 158-9
fr.776 164-7
fr.777 163
fr.779 p.73, 1-10 168-77
pp.74-5,
1-35 178-213
fr.781 pp.75-6, 1-37 214-250
fr.783 160-2
pp.76-8,
42-79 251-88
pp.78-9,
1-39 289-32
FRAGMENTA ADESPOTA
See Lyrica adespota
Hes.Fr. = HESIODUS Epic.
TLG 0020, 004, 007
Rzach to Merkelbach-West (comparatio pp.227-229).
Hippon. = HIPPONAX
Iamb.
TLG 0233, 001
(Bergk II pp.460-500, to IEG I pp.109-171, Degani; GIP
pp.342-499.)
LSJ IEG
I Degani
1 3;
3a 1
+ 2
2 4;
4a 3
3 2 4a
4 5 26
5 6 6
6 7 27
7 8 28
8 9 29
9 10 30
10 136 144
11 95a 19
12 15 18
13 1 187
+ 17
14 12 20
15 42 7
16 32 42a
17 32 42b
18 32 42b
19 34 43
20 36 44
21A 35 10
21B 23 11
22A 43 5
22B 44 45
23 24 9
24 148a 13
25 173 14
26 118a 15
27 142 16
28 64 215
29 68 66
30 38 47
31 25 35
32 47 51
[End of
Equivalence Table extract]
Cultural Heritage Language Technologies
IST
–2001-32745
September 1, 2003– November 30, 2003
Workpackage 2: Word Profile Tools
University of Missouri, Kansas City
Faculty of Classics
Cambridge University
Bruce Fraser
Jeffrey A. Rydberg-Cox
A.A. Thompson
1.
Summary of key indicators of project progress
1.1 Overview
of objectives
The practical tools under development in Workpackage
2 can be divided into three groups:
1) Multi-lingual retrieval facilities for digital
library systems (DLSs).
2) Vocabulary profile tools for texts and corpora (in
DLSs).
3) Syntactic parsing tools for Greek texts.
1.2 Overall
assessment of main milestones, results, or deliverables
In this period, our work has focused
most intensively on the development of our multi-lingual information retrieval
tool. Our primary focus has been
research into methods for the extraction of translation equivalents for our
multi-lingual information retrieval tool.
We have a few methods already implemented and this research continues in
the current period. We have also
developed a base user interface for the tool that will be further refined in
the next period.
2. Work Progress Overview
2.1
Specific objectives for the reporting period
We have had two specific objectives for this
reporting period.
1. To
develop a system to automatically extract translation equivalents from parallel
corpora
2. To
develop an initial user interface for the multi-lingual IR tool.
2.2
Achievements
Our achievements
in this work are best explained by excerpts from an article written by members
of the CHLT consortium that is currently under review with the Joint Conference
on Digital Libraries.
Cross-lingual information retrieval is a particularly
intriguing technology for students and scholars of Ancient and Early-Modern
Greek and Latin or Old Norse.
Works written in these languages are extremely important for
understanding our literary, scientific, and intellectual heritage, but these
languages are difficult and few people know them well. In particular, this technology can be
extremely useful for non-specialist scholars and students who are somewhat
familiar with these languages, but who do not know enough to form a
mono-lingual query for a search engine.
Students of Ancient Greek literature, for example, might want to know
more about the quality of ‘cunning intelligence’ that is admired and
exemplified in the character of Odysseus in Homer’s Odyssey. Because this quality is multifaceted, it would be very difficult
for readers to formulate a query for this type of passage if they were working
only with an English translation of the text; they must rely on the consistency
of the translator. A cross-lingual information system, on the other hand, would
help students identify key phrases — such as the Greek word for cunning
intelligence, ‘metis’ — and then study the passages where they appear.
Such a system is, of course, only the beginning. At best, it can identify passages that
need further study and translation since a user who cannot formulate a query
probably cannot easily read the
text in its original language either.
While a great deal of work has been done on these sorts of systems in
venues such as the Cross Lingual
Evaluation Forum (CLEF) and the
Translingual Information and Detection program (TIDES), their
focus has largely been on business journals, newswires, and national security
applications. Our work has focused
on evaluating how the needs of students and scholars in the humanities differ
from those in other domains and developing a system to meet these needs.
The problem of multi-lingual information retrieval is
essentially one of machine translation on a very small scale. There have been two dominant approaches
to this problem: 1) dictionary translation using
machine-readable multi-lingual dictionaries and 2) automatic extraction of
possible translation equivalents by statistical analysis of parallel or
comparable corpora.
Dictionary translation is a low-cost search
technology that translates queries by substituting each word in a query with
translations automatically derived from the machine-readable dictionary. This approach by itself is not very
good, achieving results that are only 40-60% as effective as a mono-lingual
search. The primary problems of
this approach are related to the introduction of extraneous words and ambiguity
into the query due to the multiple senses contained in most dictionary entries,
the failure of most machine-readable dictionaries to account for technical terms
in a consistent way, and the loss of important fixed phrases.
Automatic extraction of translation equivalents from
parallel or comparable corpora introduces similar sorts of ambiguity and
carries two additional problems: 1) these corpora can be extremely expensive to
produce, and 2) these automatically extracted translation equivalents are most
effective in restricted domains.
The needs and nature of our user community of
students and scholars in a humanities digital library suggest that we can profitably
adopt both of these approaches if we take appropriate steps to reduce query
ambiguity. The nature of the
corpus of Ancient Greek and Latin and Old Norse texts makes it ideal for this
project, as it is highly domain specific within some broad parameters. Further,
the corpus itself is very stable, so the cost of creating a parallel corpus is
finite and the investment, once made, would have lasting value for students and
scholars in its field. At the same
time, these ancient languages have been highly studied and thus can benefit
from the work of scholars who have developed comprehensive ‘unabridged’ lexica
as well as domain specific dictionaries for both fields of discourse and
specific authors.
The information-seeking behaviors of the people who
use digital resources in these languages also inform our approach. Students and scholars of ancient
languages are almost a ‘hyper-fit’ for the profile of a user of a multi-lingual
information retrieval facility.
Very few specialists are trained to write and speak Greek, Latin, or Old
Norse; advanced training — for the most part — focuses on reading these
languages. This focus on reading,
however, means that the user community is trained in a philological approach
that focuses on the use of small families of words and that is attuned to the
shades of overlapping meanings of different words. The example in the introduction of a scholar studying
‘cunning intelligence’ is not random but drawn from a book-length study of the
word metis. Further, even the most skilled readers
of ancient languages are well versed in the use of reference works such as
grammars and dictionaries and accustomed to using them regularly as they
read. Classicist Martin Mueller
describes the user community as follows:
“Very few readers know ancient Greek well enough to read it without
frequent recourse to a dictionary or grammar, and because of their highly
specialized interests, the few readers who can do so are likely to be
particularly intensive users of such reference works”.
The nature of our user community means that they are
well equipped to help translate their query into the target language as long as
they are provided with tools to help them in this process. In 1972, Salton
demonstrated that with carefully constructed query expansion thesauri,
multi-lingual information retrieval tools could be as effective as mono-lingual
tools ([13]). The information retrieval community has, however, eschewed
Salton’s arguments for hand- constructed query expansion thesauri in favor of
solutions that are more general and domain independent (i.e. [5], [8]). Salton’s carefully constructed thesauri are still expensive
but this is an expense that can reasonably be shifted to each end user at query
time for humanities applications. A tool that helps them give feedback during
the query translation process allows users to construct their own ad hoc query expansion thesauri, thus facilitating the construction
of a query that is most useful for their needs. This approach does not preclude automatic disambiguation
methods; as we will demonstrate below, we have developed a user feedback mechanism
with tools to help end-users translate queries including easy access to machine
readable dictionaries and several query-specific statistical measures that
assist users’ identification of relevant search terms.
The search facility begins with a simple interface
that allows users to enter their search terms in English, to select the sources
that will be used for query translation, and to restrict their results to words
that appear in works written by a particular author.

Figure 1: Query Entry Screen
Several of the options presented to the user in this
phase are integrated with the larger digital library system and designed to
scale up as new texts and reference works are added. The system for dictionary translation is based on a piece of
middleware with a modular design that automatically extracts translation
equivalents from any SGML or XML dictionary tagged in accordance with the
guidelines of the Text Encoding Initiative or any other user defined DTD. The author list restrictions are
generated from the cataloging metadata from the digital library.
After entering query terms, the user is presented
with an interface with detailed information to allow them to construct the best
translation of the word for their needs.
This process can range from the simple elimination of obvious ambiguities
and mistakes to a careful consideration of every term. The interface provides a list of
translation equivalents for the word or words that the user entered along with
an automatically abridged English definition of the word, a link to the full
definition for each word, a list of authors who use the words, and data about
the frequency of each word in works by the selected authors.

Figure 2: Query Translation Screen
2.2.1
List of Deliverables
D2.3: Tool to Extract Corpus Based Thesauri from Corpora: available on-line at
http://icarus.umkc.edu/mlir/mlir1.php
2.2.2
Progress of Workpackage/Tasks
We are on track to deliver D2.4 on
time.
2.2.3
Work planned for next reporting period
Continued work on multi-lingual
information retrieval tool with a particular focus on query expansion,
development of translation equivalents based on Chi2 scores, and integration of
this tool with the visualization tool developed under WP1.
3.2 Co-operation within the consortium, including
project meetings
Consortium liaison meeting in Kansas
City, with representatives of all participating institutions, November 2003.
_______________________________________________________________________
Annex 1: Equivalence Table for poetic texts (extract):
Carm.Pop. =
CARMINA POPULARIA TLG
0295, 001
(Bergk III pp.654-88 to PMG pp.449-470; GL V
pp.232-269.)
LSJ PMG
1 3 849
2 34 880
3 PMG,
Fr.adesp. 37 = 955
4 26 872
5 33 879
6 25 871
7-8 5 851
9 31 877
10 16 862
11 33 879
12 14 860
13 1 847
14 17 863
15 20 866
16 19 865
17 18 864
18 24 870
19 6 852
20 30 876
21 30 876
22A 30 876
22B 15 861
23 22 868
24 4 850
25 35 881
26 13 859
27 7 853
28 IEG
II p.11, Adesp.eleg. 17
(TLG
0234, 001 Elegiaca adespota)
29 Ath.
10.455D (83, 2-3)
30 Tryphon
p.193, 18
31 Ath.
10.453B (78, 22)
32 Ath.
10.453B (78, 23)
33 Ath.
10.455D (83, 8)
34 IEG
II p.93, Panarces (a)
35 Plu.
Quom.adul. 54 B 6
36-38 Ath.
14.648F (60, 10-20)
LSJ PMG
39 28 874
40 IEG
II p.8, Adesp.eleg. 7
(TLG 0234, 001 Elegiaca adespota)
41 2 848
42 36 882
43 23 869
44 27 873
45 21 867
46-47 Coll.Alex.
pp.173, 138
Corinn. = CORINNA
Lyr.
TLG 0294, 001
(Bergk III pp.543-53 to PMG pp.325-45; GL IV
pp.18-69.)
LSJ citations marked "Corinn.Supp." are given separately.
LSJ PMG
1 5 658
2 9 662
3 20 673
4 10 663
5 8 661
6 6 659
7 3 656
8 16 669
9 4 657
10 11 664
11 13 666
12 31 684
13 2 655
14 22 675
15 22 675
16 22 675
17 22 675
18 22 675
19 7 660
20 2 655
21 11 664
22 25 678
23 21 674
24 24 677
25 26 679
26 23 676
27 33 686
28 1 654
29 15 668
30 17 670
31 18 671
32 12 665
33 19 672
34 35 688
35 27 680
36 28 681
37 29 682
38 30 683
40 32 685
41 34 687
42 36 689
Corinn.Supp.
LSJ PMG
1 1
(a) col. 1 654
(a), col. 1
2 1
(a) col. 3 654
(a) col. 3
Cypr. = CYPRIA
TLG 1296, 001 (Bernabé)
Allen 118-125, Kinkel 15-32, Davies, Bernabé, West.
Allen K. Davies
Bernabé West
1 1 1 1 1
2 2 2 2
3 2 3 3 4
4 3 4 4 5
5 4 5 5 6
6 5 6 8 9
7 6 7 9 10
8 7 9 11 15
10 12 13 12
11 9 13 15 16
12 8 11 14 14
13 10 15 17 18
14 11 p.75,
4 21 19
15 12 17 24 20
16 13 p.160,
4 25 21
17 14 18 26 22
18 15 21 27 23
19 16 22 28 24
20 17 19 29 26
21 18 20 30 27
22 19 23 31 28
23 20 24 18 29
24 21 26 32 30
25 22 25 33 31
26 p.52.n. 34
Epigoni
TLG 1351, 001 (Bernabé)
Allen 115, Kinkel 13-14, Davies, Bernabé, West.
Allen K. Davies
Bernabé West
1 1 1 1 1
2 2 p.74,
1 5 3
3 3 2 2 5
4 4 3 3 4
E. = EURIPIDES Trag.
TLG 0006
Most frr. in LSJ are from Nauck, and retain the same numbers
in TLG (as work 020). They include most of the passages in Diggle Phaeth.
(many of which also appear as TLG work 023).
Frr. collected in CCL have Nauck numbers in the text and
apparatus, and follow Diggle for Phaeth.
Recent frr. appear in Austin, and in the collections of
Jouan-Looy (who cite the numbering of Kannicht and Mette 'E.'), and Kannicht.
Frr. are organised in four groups: from Nauck to Diggle, Hyps., other named plays, and plays cited only in the LSJ
Authors and Works listing.
1) Frr. from Nauck
to page numbers in Diggle TGFS:
Nauck Diggle
TGFS
187; 206 pp.85-6
228
94
282 96
285; 286; 292 98-100
360 101
362 104
453 114
472; 997
115-6
484; 494; 495; 499 122-4
506 127
670 131
752 135
771; 772 151
777-9; 781 156-7
821 162
819 165
839 166
898; 910; 912 167-9
2) E.Hyps. is mapped from Hunt to Bond (TLG
work 026). LSJ cites variably by fr., sometimes column, and line. See also CCL
II, Jouan-Looy 3 pp.176-223.
LSJ Bond
1 I
i
1 ii I
ii
I iii I
iii
I iv I
iv
3 (1) or 3 (1) i I
i
3 ii or 3 (1) ii I
ii
iii or 3 iii I
iii
3 (1) iv or
5 or 5 (3) I
iv
7 or 9 7
16 (18) 18
32 or 32 (58) 58
34 or 34 (60)
or 34 (60) i 60
41 or 41 (64) 64
44 70
57 57
60 or 60 i 60
64 64
3) Other named plays
(marked with an asterisk in the LSJ Authors and Works listing)
are cited from Arnim. The letter 'A' is sometimes appended (details below).
Most appear in Page Select Papyri (TLG work 029).
E.Antiop.
is usually cited by papyrus column A or B (mostly preceded by ii or iv
respectively) and line number, with 'A', 'Arn.', or 'Arnim' following.
Occasionally, Arnim page numbers are given. See also CCL II, Jouan-Looy 1
pp.240-274.
Arnim Page
ii A 7 A (Nauck
fr.185, 3)
iv B (line) A
(or Arn. or Arnim) fr.10
B 58 p.21 A fr.10, 58
p.21 A fr.10, 66
(Other fragments from column A are collected in Nauck as
frr.179, 181,
183-221, and also appear in Arnim).
E.Cret.
(Also see CCL I,
Jouan-Looy 2 pp.322-32.)
(line) fr.11
E.Melanipp.Capt.
(CCL I, Jouan-Looy 2 pp.384-96.)
Fr.6.11 fr.13, 7
E.Melanipp.Sap.
(CCL I, Jouan-Looy 2 pp.376-384.)
Prol.15 fr.14, 15
E.Oen.
(Jouan-Looy 2 pp.468-75.)
p.39 A or fr.4 A fr.28
(Other frr. from Arnim - p.39 fr.6, p.39 fr.5 and p.40 fr.6
- are collected in TLG as work 030.)
E.Pirith.Oxy.2078
Fr.1.14 fr.15a, 8
E.Sthen.
(CCL I, Jouan-Looy 3 pp.22-7.)
Prol.25 fr.16, 18
Prol.35 fr.16, 28
p.44A fr.16, 18
4) Despite the Authors
and works listing, E.Archel. is not cited by LSJ. The passage in Arnim is
published by Austin as fr.19 (TLG work 021). See also CCL II, Jouan-Looy
1 pp.292-307.
Frr. from E.Phaëth. are collected in Diggle Phaeth. (TLG
work 023). They are cited in LSJ only by Nauck fragment numbers, which are
given here, with the other passages in Arnim, matched to Diggle. (See also CCL
I, Jouan-Looy 3 pp.248-67.)
Nauck Arnim Diggle
fr.771 p.67, 1-5 1-5
fr.772 p.68, 6-7 6-7
pp.68-9,
1-37 8-43
fr.773 pp.69-72, 1-77 44-120
fr.774 p.72, 86-8 124-6
pp.72-3,
89-118 127-57
fr.775 158-9
fr.776 164-7
fr.777 163
fr.779 p.73, 1-10 168-77
pp.74-5,
1-35 178-213
fr.781 pp.75-6, 1-37 214-250
fr.783 160-2
pp.76-8,
42-79 251-88
pp.78-9,
1-39 289-32
FRAGMENTA ADESPOTA
See Lyrica adespota
Hes.Fr. = HESIODUS Epic.
TLG 0020, 004, 007
Rzach to Merkelbach-West (comparatio pp.227-229).
Hippon. = HIPPONAX
Iamb.
TLG 0233, 001
(Bergk II pp.460-500, to IEG I pp.109-171, Degani; GIP
pp.342-499.)
LSJ IEG
I Degani
1 3;
3a 1
+ 2
2 4;
4a 3
3 2 4a
4 5 26
5 6 6
6 7 27
7 8 28
8 9 29
9 10 30
10 136 144
11 95a 19
12 15 18
13 1 187
+ 17
14 12 20
15 42 7
16 32 42a
17 32 42b
18 32 42b
19 34 43
20 36 44
21A 35 10
21B 23 11
22A 43 5
22B 44 45
23 24 9
24 148a 13
25 173 14
26 118a 15
27 142 16
28 64 215
29 68 66
30 38 47
31 25 35
32 47 51
[End of
Equivalence Table extract]
Cultural
Heritage Language Technologies
IST –2001-32745
1 December 2003 – 28 Feb, 2004
Workpackage
2: Word Profile Tools
University
of Missouri, Kansas City
Faculty
of Classics, Cambridge University
Bruce
Fraser
Jeffrey
A. Rydberg-Cox
A.A.
Thompson
1.
Summary of key indicators of project progress
1.1 Overview
of objectives
The practical tools under development in Workpackage 2
can be divided into three groups:
1) Multi-lingual retrieval facilities for digital
library systems (DLSs).
2) Vocabulary profile tools for texts and corpora (in
DLSs).
3) Syntactic parsing tools for Greek texts.
1.2 Overall
assessment of main milestones, results, or deliverables
In this period, our work has continued to focus on
the development of our multi-lingual information retrieval tool. In our previous phase, we worked to
extract translation equivalents from multi-lingual dictionaries. In this period, we worked on methods
for query expansion and extraction of translation equivalents from parallel and
comparable corpora. We have also
refined our user interface and begun to think about the integration of our work
with the results of WP1. We have
also submitted two articles for publication based on our work, one to the
European Community Conference on Digital Libraries and one to the New England
Classical Journal.
2. Work Progress Overview
2.1
Specific objectives for the reporting period
We have had four specific objectives for this
reporting period.
1. To
develop a system to automatically extract translation equivalents from parallel
and comparable corpora
2. To
develop methods for query expansion within the multi-lingual information
retrieval tool.
3. To
integrate our work with the results from WP1
4. To
begin disseminating our results in published venues
2.2
Achievements
Automatic Extraction of
Translation Equivalents:
Our research into the automatic
extraction of translation equivalents from parallel and comparable corpora in
this period focused on determining whether the work of Church and Gale for the Oxford
English Dictionary can be applied to our
parallel corpora of Greek texts with English translations and Latin texts with
English translations. Church and
Gale argue that a c2 test
can be used to determine translation equivalents in parallel corpora aligned at
the sentence level. They posit a
null hypothesis that words occur in parallel sentences independently or by
chance. This null hypothesis is then compared with the actual count of term
co-occurrence across parallel corpora block using the following equation:
 with O equal to
the number of times that a word pair appears together and E equal to the
average number of times that the terms would appear together if they were
evenly distributed across the entire corpus. Our hope is that we will be able to generate a dynamic
thesaurus of translation equivalents based on our corpora and offer this
thesaurus to our users alongside the machine-readable dictionaries that we are
currently using in this interface.
with O equal to
the number of times that a word pair appears together and E equal to the
average number of times that the terms would appear together if they were
evenly distributed across the entire corpus. Our hope is that we will be able to generate a dynamic
thesaurus of translation equivalents based on our corpora and offer this
thesaurus to our users alongside the machine-readable dictionaries that we are
currently using in this interface.
Church and Gale’s results are
intriguing, but it is necessary for us to determine if they can be applied to
texts written in Greek and Latin.
So far, we have focused our investigations in three key areas.
First, Church and Gale worked on business documents written
in English and French drawn from the Union Bank of Switzerland corpus. Greek and Latin have much more complex
morphological structures and very free word order, so it is necessary to study
the impact of these linguistic differences when applying this algorithm.
Second, our corpora are aligned
with a much lower level of granularity than the corpus tested by Church and
Hanks. Scholars traditionally
refer to classical texts using a standard system, such as line number for
poetry or page/paragraph numbers of an early printed edition for prose. For example, the works of Plato are
referenced by a pagination system from a three-volume collection of Plato’s
works published in 1578 by Henri Estienne. The three volumes were numbered consecutively and each page
was divided into sections with the division marked by the letters a-e. Plato’s dialogues are cited using
the name of the dialogue, the page number from this edition, and the letter
from the section containing the beginning of the citation. Other prose works are divided in
similar ways based on other early printed antecedents. Our parallel corpora of prose
are aligned at this level and the resulting blocks can range from a few hundred
words to almost one thousand words.
Poetry is even more complicated because line numbers offer a false sense
of precision. In actuality, the
number of lines in a translation can vary widely between the original and the
translation and — even when this is accounted for — word order conventions are
so different that words could appear on widely different lines. We have obtained good preliminary
results by working with aligned segments of ten lines, but we need to determine
if this lower level of granularity will work generally across our corpora or –
alternately - if we need to
explore methods for working with comparable corpora rather than parallel
corpora.
Finally, this approach is similar
to our query expansion routine in that it favors recall over precision. We will need a detailed study of our
results to determine whether or not the information we are adding is useful to
users as they are translating their queries.
Query Expansion
One of the challenges of the sort of multi-lingual information
retrieval system that we are developing is the dependence on a match between
the concept that the user wants to study and the translation equivalents
provided in the dictionary entry for the word. For example, a user interested
in searching for Greek words that might mean ‘story’ will find several very
good translation equivalents, including the Greek word muthos that means “speech, story or tale” and is cognate
with the English word ‘myth,’ as well as other words such as ainos, meaning
“tale or story,” and polumuthos,
a compound word meaning “much talked of, famous in story.” The first phase will, however, miss
other related words that do not happen to have the word ‘story’ as part of
their definition, such as epos,
defined as “that which is uttered in words, speech, tale.”
To address this problem, we have
developed a system that provides users with a query expansion option to suggest
other words that are related to the exact matches returned by their initial
query. These related terms are
generated by an analysis of the definitions contained in the electronic
machine-readable multi-lingual dictionaries. This process involves extracting all of the translation
equivalents from the dictionaries and stripping suffixes from the translation
equivalents using Porter’s algorithm.
We exclude translation equivalents where 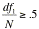 with N equal to the
number of definitions in the dictionary.
The terms themselves are assigned a binary weight rather than a weight such
as tf x idf. Our experiments with
various weighting schemes revealed that they had very little impact on the
results because documents were very short (just over four words on
average). Having developed this
index, we determine the entries that are most similar to each other using a
simple Dice similarity coefficient (
with N equal to the
number of definitions in the dictionary.
The terms themselves are assigned a binary weight rather than a weight such
as tf x idf. Our experiments with
various weighting schemes revealed that they had very little impact on the
results because documents were very short (just over four words on
average). Having developed this
index, we determine the entries that are most similar to each other using a
simple Dice similarity coefficient ( ). The five
words with the highest correlation coefficient are then included in the results
for the query translation phase of the process.
). The five
words with the highest correlation coefficient are then included in the results
for the query translation phase of the process.
In many cases – as in the above
example of a search for the word ‘story’ - this process enhances what are
already very good search results.
By its nature, this process expands recall at the expense of precision,
thus running the risk of presenting the user with too much irrelevant
information in the query translation phases. Therefore, a user seeking a more precise query can switch
off the query expansion function.
Integration
Integration
work in this period focused primarily on the refinement of the common API and
indexing format that we had previously agreed on. Our initial specification was too closely linked to the
Perseus text display system and we wanted to be sure that the visualization
tool of WP1 would be usable with any text display system.
Publication
The
article that we submitted in the last period to the Joint Conference on Digital
Libraries to be held in May in Tuscon, Arizona was accepted as a poster. A revision of this article was
submitted to the European Community Digital Libraries Meeting and a second article
was submitted in this period to the New England Classical Journal.
2.2.1
Progress of Workpackage/Tasks
We are on track to deliver D2.4 on time.
2.2.2
Work planned for next reporting period
Continue to work to refine the
extraction of translation equivalents based on Chi2 scores, integration of this
tool with the visualization tool developed under WP1, and preparation of the
tool for final release.
Cultural
Heritage Language Technologies
IST –2001-32745
1 March, 2004 – 31May, 2004
Workpackage
2: Word Profile Tools
University
of Missouri, Kansas City
Faculty
of Classics, Cambridge University
Jeffrey
A. Rydberg-Cox
Bruce
Fraser, A.A. Thompson
1. Summary of key indicators
of project progress
1.1 Overview of
objectives
The
practical tools under development in Workpackage 2 can be divided into three
groups:
1)
Multi-lingual retrieval facilities for digital library systems (DLSs).
2)
Vocabulary profile tools for texts and corpora (in DLSs).
3) Syntactic
parsing tools for Greek texts.
1.2 Overall assessment of
main milestones, results, or deliverables
In this period, our work has
focused on evaluation and integration of user feedback into the word profile
tool. During the reporting period,, we have been working on text quality,
integrating modern readings and adjusting the XML structure of the source
texts, in two ways:
1) Creating finer 'chunking' by
adding milestones, so that the software can more precisely identify the textual
contexts for each word.
2)
Adjusting the coding for suprasegmental and metrical symbols, so the texts can
be displayed on a wider range of HTML readers, including non-Unicode systems
continued to
focused on the development of our multi-lingual information retrieval tool.
We
have also continued our work extracting translation equivalents from parallel
and comparable corpora and integration into the results of WP1.
2. Work
Progress Overview
2.1
Specific objectives for the reporting period
We have had
five specific objectives for this reporting period.
1. To develop a finer system for chunking
texts in the word profile tool so that we can better identify the contexts for
each word and better align comparable segments of our corpus.
2.
To improve display of metrical and other non-alphabetic
characters in Greek texts
3.
To improve the XML document structure and the XSL rendering
system for the Greek Lexicon
4.
To extract translation equivalents from our comparable Greek
and Latin corpora
5.
To integrate our work with the results from WP1
2.2
Achievements
Text Chunking and Display
Because we were dealing with legacy
texts that were encoded before SGML became a standard format, we have
encountered problems when converting these texts to XML so that they could be
used in the Perseus text display system and as part of the word profile
tool. Therefore, it has been
necessary for us to engage in some
text clean-up and encoding
in order to resolve these problems.
Example 1:
Input text for fragment on potsherd (Sappho 2):
deurumc2000;m?ekrhta?"?!pª º!nau'on
a[gnon o[ppªaiº cavrien me;n a[lso"
malivªanº, bw'moi c2000;demiqumiavme-
#6noi ªliºbanwvtwi: (5)
ejn dæ u[dwr yu'cron kelavdei diæ u[sdwn
malivnwn, brovdoisi de; pai'" oj cw'ro"
ejskivastæ, aijqussomevnwn de; fuvllwn
#6kw'ma c2000;katagrion:
ejn de; leivmwn ijppovboto" tevqale (10)
c2000;tw?t!!!i?rinnoi"c2000; a[nqesin, aij dæ a[htai
mevllica pnevoisin ª
#6ª º
e[nqa dh; su; stevmÃmatæ> e[loisa Kuvpri
crusivaisin ejn kulivkessin a[brw" (15)
ojmÃme>meivcmenon qalivaisi nevktar
#6oijnocovaison
Output text for same fragment:
deurum¶mekrhta".pª
º.nau'on
a[gnon o[ppªaiº cavrien me;n a[lso"
malivªanº, bw'moi ¶demiqumiavme-
-noi ªliºbanwvtwi: (5)
ejn dæ u[dwr yu'cron kelavdei diæ u[sdwn
malivnwn, brovdoisi de; pai'" oj cw'ro"
ejskivastæ, aijqussomevnwn de; fuvllwn
-kw'ma ¶katagrion:
ejn de; leivmwn ijppovboto" tevqale (10)
¶twt...irinnoi"¶ a[nqesin, aij dæ a[htai
mevllica pnevoisin ª
-ª º
e[nqa dh; su; stevm<matæ> e[loisa Kuvpri
crusivaisin ejn kulivkessin a[brw" (15)
ojm<me>meivcmenon qalivaisi nevktar
-oijnocovaison
Translation of same fragment:
Hither to me from Crete to this holy temple,
where is your delightful grove of apple-trees, and altars
smoking with incense;
there cool water babbles through
apple-branches, and with roses is the whole place
shadowed, and from the shimmering leaves
the sleep of enchantment comes down;
there too a meadow, where horses graze,
blossoms with spring flowers, and the winds
blow gently...
there, Cypris, take...and into golden cups pour nectar
mingled with our festivities.
Example 2:
Input text for very corrupt papyrus fragment (Alcaeus
77A):
. . . ª º ª
ª º ª
ª º!n c3000;15"ªc3000;15 @ c3000;15ªc3000;15
ª ºasp?o?ª!!ºnª c3000;15!ªc3000;15 @
c3000;15ro"ªc3000;15 (5)
ª º!a?i" c3000;15d#9pro"ªc3000;15 @
c3000;15dhprwªc3000;15
ª º c3000;15cortouªc3000;15 @ c3000;15#6toueriouªc3000;15
ª ºman c3000;15toutope?!ª!!!ºk#9th!ªc3000;15 @
c3000;15oisatrapaifª!!!ºu?sint?hªc3000;15
ª º c3000;15upodhmataupedh"?ª!º!h!ªc3000;15 @
c3000;15#6boeiouentosqenpil?ªc3000;15
ª º c3000;15tragwdedhsanwtwamfiªc3000;15 @
c3000;15tiaponwtoudrakouperªc3000;15 (10)
ª º!: c3000;15epeidhsterroterac3000;zc3000;wªc3000;15 @
c3000;15hantragoudederma?p?e?ªc3000;15
ª ºp?athr @ c3000;15ou!onpate?r?ªc3000;15
ª ºn"!!!ª º c3000;15ª!ºug#9anemo?"?ªc3000;15 @
c3000;15ª ºt?owsanento?ªc3000;15
ªº!!!ª ºwi c3000;15ª º%32?anemwnou!ªc3000;15
ªºmw!ª ºke?n ª (15)
ª ºkª ºovmaª!º!c3000;15gmwª4iº4c3000;31Nc3000;31c3000;15 @ c3000;15oiaioleissiª
ºnt#19!!!!ªc3000;15
ª ºkuvq!ª º c3000;15pollª!ºnlegoianth?!ªc3000;15 @
c3000;15ª!ºapfwkat?ª!!!ºgl?ªc3000;15
ª º c3000;15panta?deosamoid?h?ªc3000;15 @
c3000;15ºr?iseno"!ª!!º!n?ag!!!!ªc3000;15
@ c3000;15ºouousiosde?!!!ªc3000;15 @ c3000;15º!!!!ªc3000;15
@ c3000;15º!!!ªc3000;15 (20)
. . .
Output text for Alcaeus 77A:
. . . ª º ª
ª º ª
ª º.n "ª
ª
ª ºaspoª..ºnª .ª
ro"ª (5)
ª º.ai" d pro"ª
dhprwª
ª º cortouª
toueriouª
ª ºman toutope.ª...ºkth.ª
oisatrapaifª...ºusinthª
ª º upodhmataupedh"ª.º.h.ª
boeiouentosqenpilª
ª º tragwdedhsanwtwamfiª
tiaponwtoudrakouperª (10)
ª º.: epeidhsterroterazwª
hantragoudedermapeª
ª ºpathr
ou.onpaterª
ª ºn"...ª º ª.ºuganemo"ª
ª ºtowsanentoª
ªº...ª ºwi ª ºvanemwnou.ª
ªºmw.ª ºken ª (15)
ª ºkª ºovmaª.º.gmwªªiºº1N1
oiaioleissiª ºnt....ª
ª ºkuvq.ª º pollª.ºnlegoianth.ª
ª.ºapfwkatª...ºglª
ª º pantadeosamoidhª
ºriseno".ª..º.nag....ª
ºouousiosde...ª
º....ª
º...ª (20)
. . .
B) XML document structure, and XSL rendering systems:
The early development of the XML structure (DTD, 'document
type definition', to create a tailored writing environment and a
consistently-formatted ('tagged') product, was described in the previous
report. Design work started in January 2003, the DTD was produced in a series
of 30 drafts between April and September 2003.
From September-December 2003, we worked on the 'authoring
environment' (essentially, what the writers see on their computer screens),
developing the software which produces the print-quality output necessary at
the writing and proof-reading stages, and which also gives a template for the
typesetting.
Since January 2004, the writers have been tagging lexicon
entries as they are composed. This enables us to fine-tune the XML structure
and the stylesheets, in order to define the precise degree of flexibility which
we wish to retain.
Example of XSLT Styling, which creates transformations
for input into XSL-FO rendering:
<!--"Adjective
or noun entry". The most common entry type. May include
sub-headwords for
etymologically related nouns, or (for adjectival entries)
adverbial forms or
reinterpretations as other parts of speech. -->
<!--
<!ELEMENT
ANE (HG , HG2? , Summ? , S1+ , (XR | Adv | RelN | NPS)* , Extra?
Keywd?, Ann? , Ed?)>
<!ATTLIST
ANE %commonAtts; >
-->
<xsl:template
match="lex:ANE" mode="fo:block">
<fo:block
xsl:use-attribute-sets="lex:hanging-indent lex:entry-spacing">
<xsl:apply-templates
select="lex:HG" mode="fo:inline" />
<xsl:text>
</xsl:text>
<xsl:choose>
<xsl:when
test="$section-on-newline = 'true' or lex:HG2 or lex:Summ">
<xsl:for-each select="lex:HG2 | lex:Summ">
<xsl:apply-templates select="." mode="fo:inline"
/>
<xsl:if
test="position() != last()"><xsl:text>
</xsl:text></xsl:if>
</xsl:for-each>
<xsl:apply-templates select="lex:S1"
mode="fo:block">
<xsl:with-param name="number"
select="boolean(lex:S1[2])" />
</xsl:apply-templates>
</xsl:when>
<xsl:when
test="lex:S1[2]">
<xsl:apply-templates select="lex:S1[1]"
mode="fo:inline" />
<xsl:apply-templates select="lex:S1[position() > 1]"
mode="fo:block" />
</xsl:when>
<xsl:otherwise>
<xsl:apply-templates select="lex:S1"
mode="fo:inline">
<xsl:with-param name="number" select="false()"
/>
</xsl:apply-templates>
<xsl:variable name="this" select="generate-id(.)"
/>
<xsl:for-each select="key('lex:inline',
$this)[not(ancestor::*[generate-id(.) = $this])]">
<xsl:text> </xsl:text>
<xsl:apply-templates
select="." mode="fo:inline" />
</xsl:for-each>
</xsl:otherwise>
</xsl:choose>
<xsl:apply-templates
select="lex:Adv | lex:RelN | lex:NPS" mode="fo:block" />
</fo:block>
</xsl:template>
The output
from transformations like these are used as input for the XSL-FO formatter,
which then produces the PDF output.
Example of
the final PDF output:

________________________________________________
C) User Feedback
Since July 2002, students within our Department have been
undertaking intensive evaluation and feedback on the word profile tool. An
intergated methodology has been adopted: the students edit the output texts,
noting changes and possible improvements in the tool. They then reintegrate
material back into the system, by tagging lexicon entries in XML.
Our team has so far included 6 students, mostly graduates,
who have worked a total of 23 unit-weeks. In the final year of the Project, we
shall increase the team size, in order to gain the maximum benefit for the
development process.
Automatic Extraction of
Translation Equivalents:
Our research into the automatic
extraction of translation equivalents from parallel and comparable corpora has
continued in this period. Our work
has focused on using a c2 test
can be used to determine translation equivalents in parallel corpora aligned at
the sentence level.
In our last period, we identified
three potential problems that we faced in applying this algorithm to the
parallel corpora available to the project. First, was a problem of word order.
Church and Gale worked on documents written in English and French; Greek and
Latin have much more complex morphological structures and very free word order,
so it is necessary to study the impact of these linguistic differences when
applying this algorithm. In our
initial investigations, we have determined that the algorithm as constructed
focuses on words individually and does not depend on their relative position
within the sentence. Word order,
therefore, does not require any adjustments to the algorithm.
The second issue we explored was
the lower level of granularity of our corpus alignment. In our work, some of our texts are
aligned with very high degrees of granularity, almost down to the level of the
sentence in prose and within ten lines of poetry. This high level of
granularity is not consistent across our entire corpus – some works are only
aligned at the level of a chapter or even an entire document. This variability has a negative impact
on the quality of our results. We
have therefore taken time to add new milestones to many of our texts to help
address this problem.
Our current work focuses on the
fact that this method of discovering translation equivalents favors recall over
precision. We are currently engaged
in a study of our results to determine whether or not the information we are
adding is useful to users as they are translating their queries.
Integration
Integration work in this period
focused primarily on extending the programming of the multi-lingual information
retrieval tool to use the common API that has been developed for WP1.
2.2.1
List of Deliverables
No
deliverables due during this period
2.2.2
Progress of Workpackage/Tasks
We are on
track to deliver D2.4 on time.
2.2.3
Deviations if any and corrective action
None.
`
2.3
Project Reviews
2.3.1
Work planned for future
In the final year of CHLT, we are giving thought to the
eventual integration of the database with the electronic lexicon which is to be
included in the Perseus DL.
As a pilot project, we shall first link lexicon entries with
the morphological analysis being developed for the Cambridge Classics Faculty's
CATR (Computer-Assisted Text Reading) project, which is already in use for
teaching purposes.
Example CATR text with current clickable parsing system:
The analysis has here identified the form poihsaivmhn on the
first line as the 1st person singular of the optative aorist of the verb
poievw: the simple translations given here ('make', 'do') will be replaced by more
helpful definitions, which will also involve the linguistic context.

We will also
begin work on our syntactic toolbox to discover sectional preferences and
categorization frames for Greek verbs.